Introduction: The Discussion Section
Welcome to CS32!
About the Discussion Section:
The discussion section is largely review and practice of everything that was covered during lecture in the previous week, plus some greater depth.
This is the time when you ask questions that you didn't during lecture--leave nothing to chance!
The general discussion format is to review topics at the high level, examine a bunch of examples that illustrate them, and then practice them by hand.
About My Role as Your TA:
I am always available to email; don't hesitate to ask for any clarifications.
My office hours are on Wednesdays from 8:30 - 11:30am, in Boelter 3803. If you can't make those hours, and can't take advantage of the other TA office hours, email me to set up an appointment.
I grade the *style and comments* of your assignments, but not the correctness... so if you have time, entertain me with fun comments... but you know... focus on getting things right first...
Site Features:
You can now add notes inside the website so that you can follow along and type as I say stuff! Just hit
SHIFT + Nand then click on a paragraph to add an editable note area below. NOTE: the notes you add will not persist if you close your browser, so make sure you save it to PDF when you're done taking notes! (see below)The site has been optimized for printing, which includes the notes that you add, above. I've added a print button to the bottom of the site, but really it just calls your printer functionality, which typically includes the export to PDF.
A Return to CS31
The first portion of CS 32 dealt heavily with topics from CS 31, and in particular, those surrounding classes and dynamic memory.
If you're unfamiliar with my site from last quarter, here is a link to *all* of the necessary review material.
More specifically:
Structs & Classes: here is last quarter's lecture.
Dynamic Memory & More on Structs: here is last quarter's lecture.
Ah such nostalgia... it feels like just yesterday that we were learning about ints.
Why not a bit of review to get our feet wet?
Review of Resource Management
We should take a quick look back at where different variables live in memory, because it's particularly important for constructing and destruct...ing objects.
For starters, say I make variable declarations like the following:
string theory = "woah"; int* i;
With regards to scope and memory access, what do we call these variables? In what partition of memory are these variables stored?
These are local variables; they live in the partition of memory known as the stack.
Is it all coming back, like riding a bike? (fun fact: I'm terrified of bicycles)
If so, say I have the following variables:
string* getThePoint = new string("point taken");
int* redundantExample = new int(5);
Question 1: the dynamic allocation of memory like new int(5); is stored in what partition of memory?
The heap! This is where dynamically allocated variables live; it is kept distinct from the stack because variables in the heap are not deallocated upon exit from scope.
Question 2: the pointer that refers to the dynamically allocated memory ( e.g., getThePoint in
string* getThePoint = new string("point taken"); ) lives in what partition of memory?
The stack! Even though the memory that the pointer *points to* is dynamically allocated to the heap, the pointer itself lives in the stack and will disappear when it falls out of scope.
This is the very reason we have memory leaks: dynamically allocated objects persist in the heap even though we lose the capacity to point to, and then delete, them when the pointer falls out of scope.
In summary:
Stack |
Heap |
|
|---|---|---|
What variables live here? |
Local variables, functions, function arguments, etc. |
Dynamically allocated memory reserved by the programmer |
How can variables be accessed? |
By any type of identifier defined in scope |
Only through pointers! |
Memory is allocated: |
Whenever a variable is declared in scope |
Whenever the |
Memory is freed / deallocated: |
Whenever a variable disappears from scope (e.g., local variables in a function after returning from that function) |
Only after the delete keyword is used! |
Why am I re-telling this to you?
Maybe I deleted my memory of the first time...
The real reason is because it helps us dissect our class definitions, and in particular, the data members that make them up, how to construct them, and how to DESTROY them.
To do so, we need to know when certain class object events happen. Let's fill in this table:
Event |
Stack |
Heap |
|---|---|---|
Construction |
When does it happen? Local variable declarations such as: // Called 1 time string s = "hi!"; // Called 3 times! LinkedList LLCoolJ[3]; |
When does it happen? Dynamic variable declarations such as:
// Called 1 time
string* s
= new string("neat!");
// Called 3 times!
LinkedList* lists
= new LinkedList[3];
|
Deallocation |
When does it happen? Local variable leaves scope:
// Called 3 times!
for (int i = 0; i < 3; i++) {
LinkedList LLama;
}
|
When does it happen? delete or delete[] called on dynamically allocated object:
LinkedList* linky
= new LinkedList();
// Called 1 time
delete linky;
LinkedList* links
= new LinkedList[4];
// Called 4 times!
delete[] links;
|
Just to be sure we understand, let's use NoisyClass from a week ago because I'm lazy:
#include <iostream>
#include <string>
using namespace std;
class NoisyClass {
private:
string s;
public:
NoisyClass () {
cout << "[C] Default constructor" << endl;
}
NoisyClass (string stuff) {
s = stuff;
cout << "[P] Parameterized constructor" << endl;
}
NoisyClass (const NoisyClass& other) {
s = other.s;
cout << "[~] Copy constructor" << endl;
}
~NoisyClass () {
cout << "[D] Destructor" << endl;
}
NoisyClass& operator= (const NoisyClass& other) {
s = other.s;
cout << "[=] Assignment" << endl;
return *this;
}
};
With the NoisyClass definition from above, what will the following code print out?
// [C] Default constructor
// [P] Parameterized constructor
// [~] Copy constructor
// [D] Destructor
// [=] Assignment
int main () {
NoisyClass* heapsOfNoise;
for (int i = 0; i < 2; i++) {
NoisyClass n[2];
}
heapsOfNoise = new NoisyClass[2];
delete[] heapsOfNoise;
}
With the NoisyClass definition from above, what will the following code print out?
// [C] Default constructor
// [P] Parameterized constructor
// [~] Copy constructor
// [D] Destructor
// [=] Assignment
int main () {
NoisyClass* heapsOfNoise = new NoisyClass[2];
NoisyClass echo = heapsOfNoise[1];
heapsOfNoise[0] = echo;
delete[] heapsOfNoise;
}
Advanced Constructor Notes
This isn't Bob the Builder territory any more (I promise to stop using him in my constructor examples).
We spoke a bit more extensively about the details of constructors in CS31 (lecture here) but now there are a few more things to say.
First, let's introduce a new tool for our constructors: the initialization list.
An initialization list is a constructor syntax for initializing class data members *as* they are being declared.
We've previously dealt with member objects *after* they've been declared, by performing assignments *within* the constructor body.
In other words, by the time we execute the code in the body of our constructor, our data members have already been declared.
Now, when I wrote this example, we were just completing a zombie assignment in CS32 so what may have been topical then is kinda weird now... meh:
class Survivor {
private:
string m_name;
bool m_infected;
int m_health;
public:
// Default constructor
Survivor () {
// Assignments here happen *after*
// the data members have already
// been declared / had memory allocated
m_name = "Rick Grimes";
m_infected = false;
m_health = 100;
}
// Getters
string getName () {return m_name;}
bool isInfected () {return m_infected;}
int getHealth () {return m_health;}
};
Notice here that I assign values in my default constructor within the constructor body. This means that by the time I've reached my constructor body, all of the data members have had their default constructors called upon them (though primitive types will store garbage until changed).
BUT, if we use an initialization list, we will preempt this default behavior.
The initialization list syntax is as follows:
ClassName (): member_1(constructor_args_1), ..., member_n(constructor_args_n) {
// <constructor body>
}
Above, member_i represents any data members we want to initialize using the initialization list. We need not initialize every data member.
Similarly, constructor_args_i represents the arguments we're passing to that member's constructor for each member_i.
This could be a literal, function call, etc. that resolves to some argument value.
So, rewriting the above example using an initialization list:
class Survivor {
private:
string m_name;
bool m_infected;
int m_health;
public:
Survivor (): m_name("Rick Grimes"),
m_infected(false),
m_health(100) {}
// Getters
string getName () {return m_name;}
bool isInfected () {return m_infected;}
int getHealth () {return m_health;}
};
You can even use initialization lists with non-default constructors:
class Survivor {
private:
string m_name;
bool m_infected;
int m_health;
public:
Survivor (): m_name("Rick Grimes"),
m_health(100),
m_infected(false) {}
Survivor (string name, bool infected, int health):
m_name(name),
m_health(health),
m_infected(infected) {}
// Getters
string getName () {return m_name;}
bool isInfected () {return m_infected;}
int getHealth () {return m_health;}
};
Of course, you know that this is a crappy random generator because we never seeded it but... meh... too much typing.
Summary so far:
// A constructor like:
Survivor () {
m_name = "Rick Grimes";
m_infected = false;
m_health = 100;
}
// Is as though we had declared
// variables and then later initialized
// them, like:
string m_name;
bool m_infected;
int m_health;
m_name = "Rick Grimes";
m_infected = false;
m_health = 100;
// A constructor with initialization
// list like:
Survivor ():
m_name("Rick Grimes"),
m_health(100),
m_infected(false) {}
// Is as though we had instantiated
// our variables like:
string m_name = "Rick Grimes";
bool m_infected = false;
int m_health = 100;
See the extra step we shave off by using initialization lists?
"But Andrew, why do we care about shaving off the extra step? It shouldn't really matter with primitives data members..."
"Right as always, Andrew! So when do we actually see an improvement in performance?"
Thanks for playing. As it turns out, we see the benefit of using initialization lists when we have non-primitive data members.
Let's add a new class to our example:
class Weapon {
private:
string m_name;
int m_ammo;
public:
Weapon (): m_name("Colt Python"),
m_ammo(6) {}
Weapon (string name, int ammo):
m_name(name),
m_ammo(ammo) {}
string getName () {return m_name;}
int getAmmo () {return m_ammo;}
};
class Survivor {
private:
string m_name;
bool m_infected;
int m_health;
Weapon m_gun;
public:
Survivor () {
m_name = "Rick Grimes";
m_infected = false;
m_health = 100;
}
// Getters
string getName () {return m_name;}
bool isInfected () {return m_infected;}
int getHealth () {return m_health;}
Weapon getWeapon () {return m_gun;}
};
What happens when I don't include any mention of m_gun in my constructor?
Its default constructor will be called, giving it the name "Colt Python" and 6 ammo.
Alright... but what happens if I didn't want the default Weapon constructor to be called and instead used the following Survivor constructor?
Survivor () {
m_name = "Rick Grimes";
m_infected = false;
m_health = 100;
// See what's happened here?
// What gets printed?
cout << m_gun.getName() << endl;
m_gun = Weapon("Beretta", 30);
}
Here, the default Weapon constructor gets called before I get to use the second Weapon constructor to specify the Weapon members I want!
So essentially, if I do NOT use an initialization list instantiation for m_gun, I call the Weapon constructor twice.
For small classes like Weapon, this is trivial, but in large applications with large classes, it may not be!
Take the following fix for example:
class Survivor {
private:
string m_name;
bool m_infected;
int m_health;
Weapon m_gun;
public:
Survivor ():
m_name("Rick Grimes"),
m_health(100),
m_infected(false),
m_gun("Beretta", 30) {}
// Getters
string getName () {return m_name;}
bool isInfected () {return m_infected;}
int getHealth () {return m_health;}
Weapon getWeapon () {return m_gun;}
};
Here, I use the second Weapon constructor *before* the default Weapon constructor would get called.
This establishes the rough construction sequence (some items omitted):
Use the calling constructor's initialization list
Construct any remaining data members (default constructors)
Execute the calling constructor's function body
Rule of thumb: put as many member initializations as you can into the initialization list.
And, as a final, less important note:
Initialization lists serve as the only way to initialize constant data members.
Aaaand that's probably way more than you'd ever care to know about constructors. On to the bigger stuff!
More Notes on Compilation
Before we start talking about File Organization and the process of breaking large projects into constituent bits, it helps to have some greater detail on the compilation process.
You see, C++ compilation is actually a 3 step process:
Preprocessing
Compilation
Linking
Let's look at what happens at each stage:
Preprocessing
(Note: we didn't go over this yet, but I wanted to fill in a few blanks from lecture)
The preprocessing stage handles what are called "preprocessor directives" like #include and #define.
What we mean by preprocessing is that we are literally doing some file transformations before we begin processing the source into machine code.
For review:
Source code is the human-readable code that we use to create machine-readable instructions through compilation.
Machine code is the machine-executable code that we run during program runtime.
So, what preprocessing does is to prepare the source code for compilation by "replacing" each #include instance with
their respective file contents (or at least the identifiers, to be resolved later).
Lastly, since we haven't really seen it before, the #define directive does the following:
The #define directive says this: give me the name of some identifier, and before compilation, I'll replace it anywhere I see it
in the code with the literal you associate with it.
So, for example:
#define LOUD_STRING "YELLING"
#define COOL_INT 42
int main () {
cout << LOUD_STRING << endl;
cout << COOL_INT << endl;
}
Here, I say, "Before compiling, anywhere you see the identifier LOUD_STRING, replace it with (literally, the text) "YELLING". "... and similarly for the COOL_INT.
So why use #define and not a const variable?
The differences are subtle, but the main difference is that const variables abide by scope rules, whereas #define
values are applied globally.
Because #define is preprocessed, it also means you're not taking up space for another variable, though in practice this isn't a big concern.
Compilation
The compilation stage turns the source code (having been preprocessed) into machine code.
These are binary files that are called object files.
Each source code file will therefore be translated into an object file, with all of its variables, function definitions, etc. now ready to be checked by the linker.
Linking
The Linker takes the object files compiled from source in the previous step and then makes sure that, amongst any of the compiled objects and included libraries, there exists a definition for every function or variable used in the code. If not, then we get a compilation error.
Linkers then assemble all of the dependencies we've listed throughout our source, and creates the executable file, which we run to execute the code (thus the name).
Wow that was dry reading. You still awake? I fell asleep just writing that...
How about some pictures? Everyone likes pictures...
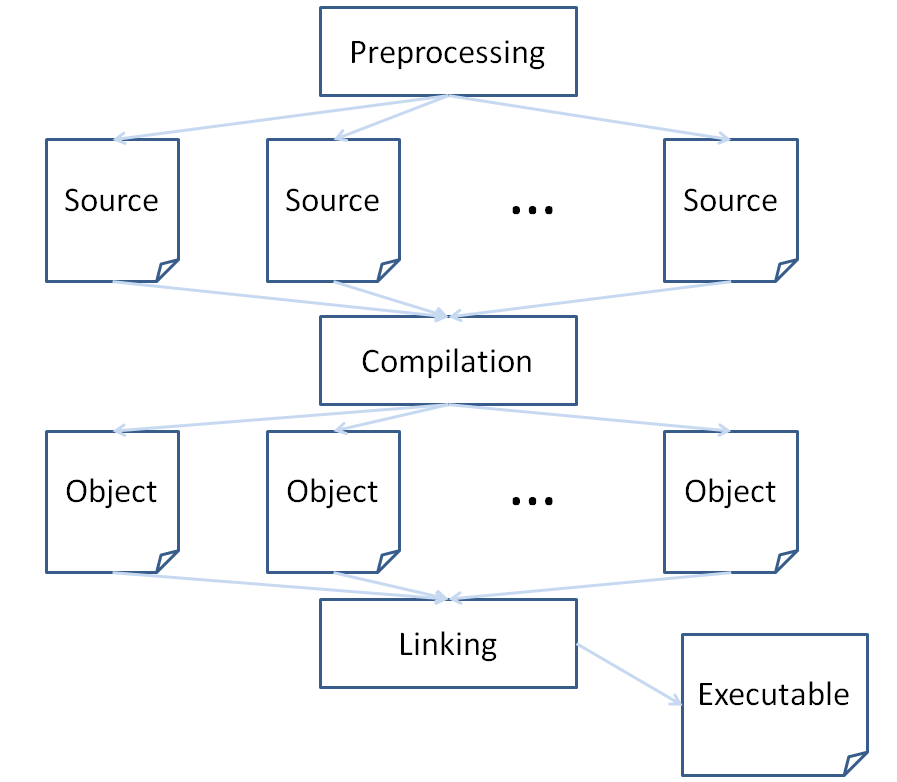
"That's one of your better illustrations, Andrew. I especially like how you ran out of room and had to throw the Executable to the side. Also, I could probably read it from space."
:(
File Organization
So now that we know a little bit about what's going on with multiple-source-file projects, let's actually see how to implement them...
I guess we should start by considering:
Why do we bother breaking down our source into different files? Isn't this just more overhead to learn?
Well, any projects of any appreciable size become ungainly if you have a file that is, say, a million lines of code long! It would be impossible to find anything.
There are also implications for version control and debugging that make breaking projects into multiple files a great idea.
Hey, here's something we haven't talked about before:
A Header File (.h) is just like a .cpp file except that by convention, we use header files to *declare* functions and variables, but .cpp files to *implement* and *use* them.
You can think of header files as contracts between you and the compiler: the headers state what you promise to implement, and the .cpp files are your fulfillment of the contract.
Headers also collect function prototypes so that it's easy to see what the expected behavior of a particular interface will be.
The process of creating header files is typically the following:
Create a new header file; by convention, we usually name it the same as the relevant .cpp file, so for example if I had
Survivor.cpp, I might make a header file calledSurvivor.h(which we'll do in a moment... be patient).Next, we put all of the necessary class definitions, function prototypes, etc. that we deem relevant to wherever that particular header file is to be included.
Finally, we invoke the preprocessor directive by
#include-ing the header file into other files in which it is relevant.
We're used to using includes to get standard library components when we say things like #include <string>.
WARNING: We use the bracketed notation on library inclusions, but the quotation notation for our custom header files. For example:
#include <cctype> // a library include
#include "Survivor.h" // a custom header include
Let's try splitting our Survivor class into a header and .cpp file.
Here's what we had before:
class Survivor {
private:
string m_name;
bool m_infected;
int m_health;
Weapon m_gun;
public:
Survivor () {
m_name = "Rick Grimes";
m_infected = false;
m_health = 100;
m_gun = Weapon("Beretta", 30);
}
// Getters
string getName () {return m_name;}
bool isInfected () {return m_infected;}
int getHealth () {return m_health;}
Weapon getWeapon () {return m_gun;}
};
Now, we'll make our two files!
Will the following implementation work? Is there something missing?
// Survivor.h
#include <string>
class Survivor {
private:
std::string m_name;
bool m_infected;
int m_health;
Weapon m_gun;
public:
Survivor ();
std::string getName ();
bool isInfected ();
int getHealth ();
Weapon getWeapon ();
};
// Survivor.cpp
#include "Survivor.h"
using namespace std;
// Initialization list style
Survivor ():
m_name("Rick Grimes"),
m_infected(false),
m_health(100),
m_gun(Weapon("Beretta", 30)) {}
string Survivor::getName () {return m_name;}
bool Survivor::isInfected () {return m_infected;}
int Survivor::getHealth () {return m_health;}
Weapon Survivor::getWeapon () {return m_gun;}
What was missing above that caused an error?
You're so smart... we have a data member of the Weapon class that our compiler doesn't know about any more! We can fix this now...
Let's split our Weapon class into a header and .cpp and see how they all fit together...
// Weapon.h
#include <string>
class Weapon {
private:
std::string m_name;
int m_ammo;
public:
Weapon ();
Weapon (std::string name, int ammo);
std::string getName ();
int getAmmo ();
};
// Weapon.cpp
#include "Weapon.h"
using namespace std;
Weapon::Weapon ():
m_name("Colt Python"), m_ammo(6) {}
Weapon::Weapon (string name, int ammo):
m_name(name), m_ammo(ammo) {}
string Weapon::getName () {return m_name;}
int Weapon::getAmmo () {return m_ammo;}
Now all I have to do is add the Weapon header to my Survivor header and I'm good to go!
I could even execute some test code with a main function in a new file:
// Survivor.h
#include <string>
#include "Weapon.h" // Added!
class Survivor {
private:
std::string m_name;
bool m_infected;
int m_health;
Weapon m_gun;
public:
Survivor();
std::string getName ();
bool isInfected ();
int getHealth ();
Weapon getWeapon ();
};
// RunIt.cpp
#include <iostream>
#include "Survivor.h"
using namespace std;
int main () {
Survivor s;
cout << s.getName() << endl;
cout << s.getWeapon().getName() << endl;
}
Notice: I don't have to include the Weapon header or .cpp in my RunIt.cpp because it's already been Linked in the Survivor.h.
Neat eh? EH?!
There's one superfluous inclusion directive in my 5-file package listed above. Can you find it?
You don't need to include the string library in Survivor.h any more because it's been included in Weapon.h, which is included by Survivor.h
Summary
Header files used to abstract common components and declarations from the meat of the source and are handy for organizing large projects.
Use header files for class and function declarations, and .cpp files for their implementations and uses.
Your header files should include whatever other files they're dependent upon, that way your .cpps that use the header files don't have to worry about including more than one for a single dependency.
Inclusion Tips & Tricks
Our example so far has had pretty tame and dull uses of the inclusion directive, and a straightforward dependence hierarchy.
LET'S RUIN EVERYTHING.
Say I wanted to add an owner data member to my weapon class that is a pointer to a Survivor, as follows:
// Weapon.h
#include <string>
class Weapon {
private:
std::string m_name;
int m_ammo;
Survivor* m_owner;
public:
Weapon ();
Weapon (std::string name, int ammo);
std::string getName ();
int getAmmo ();
};
Am I good? Will that compile?
No! Everything's wrong! Our compiler doesn't know what a Survivor is in our Weapon.h class specification.
"Well," you might remark, "Fine then, I'll just include the Survivor header and everything will be fine!"
Will the following code compile?
// Weapon.h
#include <string>
#include "Survivor.h"
class Weapon {
private:
std::string m_name;
int m_ammo;
Survivor* m_owner;
public:
Weapon ();
Weapon (std::string name, int ammo);
std::string getName ();
int getAmmo ();
};
Aieee! No, we have what's called a circular dependency because Survivor.h also includes Weapon.h:
A circular dependency exists when we have two or more class definitions that each need something from the other. When we try to include one inside of the other, it creates an infinite loop attempting to resolve the other class!
So, we use a little trick...
A forward declaration can be used to tell the compiler that a certain class exists, even though we do not fully specify its data members, public interface, or full implementation in line with the forward declaration.
So I can tell the compiler that class Survivor exists (and that I promise to give it meaning later, thanks to the Linker!), without providing the whole class definition on the spot, as follows:
#include <string>
// Forward declaration!
class Survivor;
class Weapon {
private:
std::string m_name;
int m_ammo;
Survivor* m_owner;
public:
Weapon ();
Weapon (std::string name, int ammo);
std::string getName ();
int getAmmo ();
};
Now, my compiler trusts me that there exists some Survivor class out there while resolving the circular dependency.
A warning about forward declarations:
You cannot specify an incomplete type (like above) to resolve a circular dependency when the data member needing resolution is an object, rather than a pointer to an object, of the desired class.
If you use a forward declaration with an incomplete type (like above), you cannot reference any of the pointer's public interface elements until the Linker has resolved that other class as well. Typically, this is not an issue if you separate your code into header and .cpp files.
Include Guards
Finally, let's talk about a useful and common practice with header files: include guards.
In large projects with a ton of dependencies flying back and forth trying to be resolved by the compiler, it could be easy to lose track of what you've already included and what you still need to include.
To this end, we have include guards to make sure we avoid the multiple-definition error, which occurs when we accidentally include something twice that attempts to redefine a previously defined identifier.
The include guard directive prevents the multiple-definition error by *only* performing an inclusion if it hasn't already been included. The method for doing this is to say, "If I haven't set a flag yet saying that I've included this, then set that flag and include this."
The syntax for an include guard is as follows:
// If FLAG_NAME is not defined... #ifndef FLAG_NAME // ...then define it... #define FLAG_NAME ... // Perform the necessary inclusions // and source body definitions here ... // ...up until you see the endif #endif
Let's add include guards to our example headers:
// Weapon.h
#ifndef WEAPON_INCLUDE
#define WEAPON_INCLUDE
#include <string>
// Forward declaration!
class Survivor;
class Weapon {
private:
std::string m_name;
int m_ammo;
Survivor* m_owner;
public:
Weapon ();
Weapon (std::string name, int ammo);
std::string getName ();
int getAmmo ();
};
#endif
// Survivor.h
#ifndef SURVIVOR_INCLUDE
#define SURVIVOR_INCLUDE
#include "Weapon.h"
class Survivor {
private:
std::string m_name;
bool m_infected;
int m_health;
Weapon m_gun;
public:
Survivor();
std::string getName ();
bool isInfected ();
int getHealth ();
Weapon getWeapon ();
};
#endif
Cool... now if, by some accident I included one of my headers twice on accident, I protect myself from having to perform relentless book-keeping.
Inclusion FAQ
I wrote a couple things down that I thought I should address but it's summer and I'm lazy including examples might confound good practice so:
What if I put a non-inline function implementation into a header file. Will it compile?
(Don't worry about what a non-inline function means yet--just think of the function definitions we've learned thus far)
There are a couple things wrong with that: (1) you generally want to separate your implementations into .cpp files, and (2) if you try to include that header file twice, you'll get a multiple-definition error for implementing that function twice. tl;dr: don't do it until we've learned about the inline keyword.
Can I put global constants in header files? Could there be a multiple-definition problem here?
You might run into problems with non-primitive global constants, but primitive constants are OK.
With all of these different files, how do I know what runs when I run my program?
Remember that the main function is special--it is what gets executed at runtime, regardless of what file it is in, as long as it's part of the compiled project.
Copy Constructors
Sometimes I think this class should be called "Intro to C++ Constructors."
So, say we've got this cool class:
#include <iostream>
#include <string>
using namespace std;
const int MAX_COPIES = 100;
// Kinkos is a registered trademark of FedEx
// Its use in this example is purely for bad joke
// purposes and in no way reflects the views or
// copy constructors of the company or its affiliates
class Kinkos {
private:
string copies[MAX_COPIES];
int currentCopy;
public:
Kinkos () {
currentCopy = 0;
}
string makeCopy () {
string copy;
if (currentCopy > 0) {
copy = copies[currentCopy - 1];
currentCopy--;
}
return copy;
}
void addOrder (string s) {
if (currentCopy <= MAX_COPIES) {
copies[currentCopy] = s;
currentCopy++;
}
}
};
Alright, so I have a Kinkos that takes in copy orders for string text, and then makes copies of the most recently received orders (I never said customers were happy with it).
Now, our Kinkos stores, being specialists in making copies, want to make an expansion store...
So, naturally, they copy one of their own stores!
To help them do so, they use a copy constructor...
A copy constructor is a special constructor definition that is called whenever a new object of some class C is created from another object of that same class C.
So, if I try to make a new class C object, and then create a "copy" of it, I might say:
C object1; // Make object2 a "copy" of object1 C object2(object1);
Let's create a couple of Kinkos stores and see what happens:
What will the following code output?
int main () {
Kinkos inWestwood;
inWestwood.addOrder("Don't")
inWestwood.addOrder("sue me...")
inWestwood.addOrder("FedEx");
// A copy constructor called using the source
// Kinkos object, inWestwood, creating a new
// Kinkos object expansion!
Kinkos expansion(inWestwood);
cout << inWestwood.makeCopy() << " ";
cout << inWestwood.makeCopy() << " ";
cout << expansion.makeCopy() << endl;
}
Err, ignore that output, FedEx >_> <_<
Here, we see that when I wanted expansion to be a copy of inWestwood, it copied all of the data members over as well!
How did our program know how to do this?
If a copy constructor is not defined by the programmer, a default copy constructor will be provided by the compiler. This generic copy constructor will simply attempt to create a copy of each of the source's data members, and initialize the copy's data members to these copies.
This explains why I see "FedEx sue me... FedEx" instead of "FedEx sue me... Don't" in the example above; the copies data member is itself a copy in expansion.
Now, say our Kinkos wanted to specify how many copies a given store could handle, i.e., they wanted different maximum copies for each store.
We see that having the copies data member as an array of strings won't work for this goal because its size must be constant at compile time.
So, we change our data members to work with dynamic allocation of the copies array:
class Kinkos {
private:
// [!] Changes to the data member
string* copies;
int currentCopy;
int maxCopies;
public:
// [!] Changes to the constructor
Kinkos (int maximum) {
copies = new string[maximum];
currentCopy = 0;
maxCopies = maximum;
}
// [!] Added destructor
~Kinkos () {
delete[] copies;
}
string makeCopy () {
string copy;
if (currentCopy > 0) {
copy = copies[currentCopy - 1];
currentCopy--;
}
return copy;
}
Kinkos& addOrder (string s) {
if (currentCopy <= maxCopies) {
copies[currentCopy] = s;
currentCopy++;
}
return *this;
}
};
Now, we try and run it with the same main function as above...
Will the new class definition for Kinkos function as intended?
No! Our compiler-generated copy constructor copied all of our data members when we made the expansion object... except that the copies pointer still points to the same object in both the inWestwood and expansion objects! I then try to delete this dynamically allocated array twice, causing problems at runtime (undefined behavior).
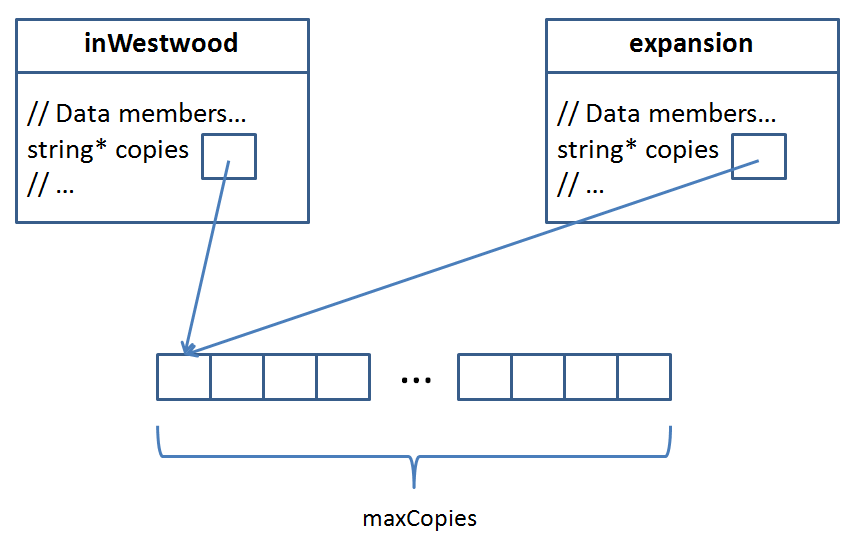
"Andrew, if you squint at that diagram, it looks a little like a mustached robot."
Thank you for that information.
So how do I get around this? I want to define my own copy constructor behavior!
Users may define their own copy constructors using the following syntax:
ClassName::ClassName(const ClassName& c) {
// Body of copy constructor
}
Notice some of the features of this syntax:
Its parameter list consists of a single object of the same type as the class for which it is a member function.
We indicate this single parameter as a const value so that we don't change anything in the object getting copied.
We indicate that this single parameter is a *reference* to another ClassName object.
Why do we indicate the copy constructor parameter as a reference to another object of the same class?
If we indicate that it is pass-by-value, then it will attempt to make a copy of the argument... which will then call the copy constructor again and again into infinite regress!
From this point, we see that:
By definition, copy constructors define the behavior of pass-by-value for a particular class.
Let's start out by fixing our Kinkos class with its own copy constructor:
class Kinkos {
private:
string* copies;
int currentCopy;
int maxCopies;
public:
Kinkos (int maximum) {
maxCopies = maximum;
copies = new string[maximum];
currentCopy = 0;
}
// [!] NEW: Copy constructor added!
Kinkos (const Kinkos& k) {
maxCopies = k.maxCopies;
copies = new string[maxCopies];
// Instead of just copying the pointer of
// the copy, I want to copy the elements of the
// pointer instead!
for (int i = 0; i < maxCopies; i++) {
copies[i] = k.copies[i];
}
currentCopy = k.currentCopy;
}
~Kinkos () {
delete[] copies;
}
string makeCopy () {
string copy;
if (currentCopy > 0) {
copy = copies[currentCopy - 1];
currentCopy--;
}
return copy;
}
Kinkos& addOrder (string s) {
if (currentCopy <= maxCopies) {
copies[currentCopy] = s;
currentCopy++;
}
return *this;
}
};
Now if I try to run my main function from before, I'm OK!
One thing to note about this copy constructor: We can access the private members of k, the Kinkos being copied, because the copy constructor is still a member function of the Kinkos class.
The two Kinkos objects now look like this:
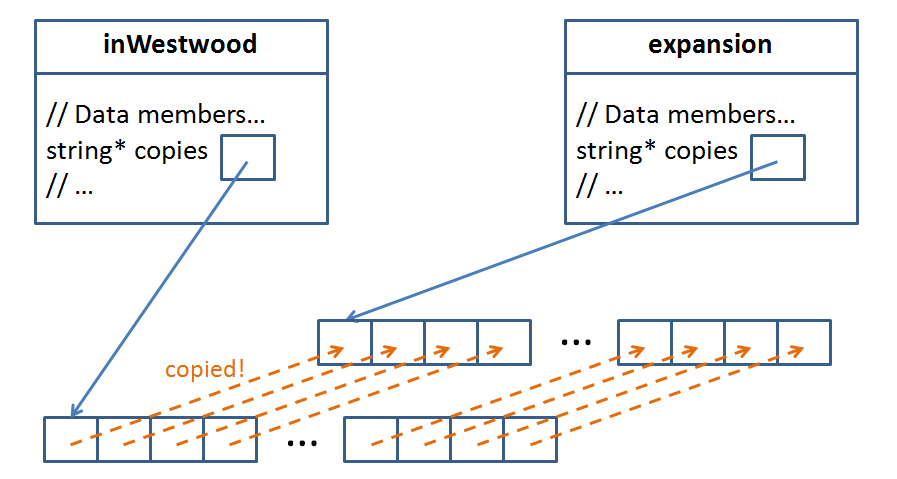
One final note about copy constructors:
We can use the assignment operator to invoke the copy constructor if both operands of the same class and the lvalue has not been declared before.
So, in our previous example's main function:
Kinkos expansion(inWestwood); // ... is equivalent to ... Kinkos expansion = inWestwood;
BUT, what if the lvalue *has* been declared before? Let's take a look in a bit...
Intro to Operator Overloading
Before we look at handling object assignment, let's take a quick review / detour into operator overloading.
Operator overloading is the act of providing user-defined behavior for different C++ operators.
When we want to define the behavior of an operator (let's say, the plus sign +) for our class, we use the syntax:
ClassName& ClassName::operator+ (SomeType other) {
// Operator behavior within
}
Let's look at a quick, arbitrary example:
What will the following code output?
struct OpExample {
string s;
int i;
OpExample () {
i = 1;
}
// [!] Using the += operator with another OpExample object
// as the rvalue will add the rvalue's string data member
// to the lvalue's string data member as many times as the
// lvalue's int data member
OpExample& operator+= (OpExample& rvalue) {
for (int j = 0; j < i; j++) {
s += rvalue.s;
}
return *this;
}
};
int main () {
OpExample op1,
op2;
op2.s = "Test!";
op1.i = 3;
// [!] Using our custom += operator definition!
op1 += op2;
cout << op1.s << endl;
}
Some things to note about our example:
Our overloaded symbol inherits the precedence rules of the C++ language.
The parameter in our class' operator overloading function definition refers to the rvalue in this case.
We return a reference to the lvalue object so that we can chain operator calls together.
Instead of saying
op1 += op2;I could have saidop1.operator+=(op2);in the main function.
Here's another example for practice!
What will the following code output?
#include <iostream>
#include <string>
using namespace std;
struct OpExample {
string s;
int i;
OpExample () {
i = 1;
}
OpExample& operator+= (OpExample& rvalue) {
for (int j = 0; j < i; j++) {
s += rvalue.s;
}
return *this;
}
// [!] New prefix increment operator! Notice how
// my operator overloading functions can return types
// other than that of the class / struct in which
// they are defined!
int operator++ () {
return i++;
}
};
int main () {
OpExample op1,
op2,
op3;
op2.s = "Test!";
op3.s = "Wow!";
++op1;
++op2;
op1 += (op2 += op3);
cout << op1.s << endl;
}
Overloading the Assignment Operator
In our segment about copy constructors, we saw that we can use the assignment operator (=) to invoke the copy constructor of the lvalue when it has yet to be declared before.
BUT, what happens if we try the following for some class C:
C c1; C c2; // [!] Will this invoke the copy constructor // for c1? c1 = c2;
Above, we see that c1 has already been declared and constructed, so the statement c1 = c2; will NOT invoke the copy constructor, but rather, the assignment behavior.
What is the assignment behavior, by default?
The default assignment behavior for an lvalue and rvalue of the same class is generated by the compiler, and will simply perform an assignment of each of the lvalue's data members to each of the rvalue's corresponding data members.
Well that's wordy and useless... why don't we examine a simple example?
#include <iostream>
#include <string>
using namespace std;
// hehe... it's short for assignment but you
// still have to say "ass example"
struct AssExample {
int m_i;
string m_s;
bool m_b;
AssExample () {};
AssExample (int i, string s, bool b) {
m_i = i;
m_s = s;
m_b = b;
}
};
int main () {
AssExample a1(3, "test", 1),
a2;
// [!] Note: a2 has already been constructed,
// so the copy constructor won't be called, but rather
// the assignment behavior will occur
a2 = a1;
cout << a2.m_i << endl;
cout << a2.m_s << endl;
cout << a2.m_b << endl;
}
Naturally, then, if I wanted to control the behavior of the assignment, I could implement an operator overloading for it in my class definition:
#include <iostream>
#include <string>
using namespace std;
struct AssExample {
int m_i;
string m_s;
bool m_b;
AssExample () {};
AssExample (int i, string s, bool b) {
m_i = i;
m_s = s;
m_b = b;
}
// [!] Define the behavior of the assignment to NOT
// copy over the string data member
AssExample& operator= (const AssExample& other) {
m_i = other.m_i;
m_b = other.m_b;
return *this;
}
};
int main () {
AssExample a1(3, "test", 1),
a2;
a2 = a1;
// [!] See what I print out now...
cout << a2.m_i << endl;
cout << a2.m_s << endl;
cout << a2.m_b << endl;
}
Just like with the compiler-given copy constructor, we can see that we might get into trouble with the compiler-given assignment behavior if one of our data members was a pointer!
As such, we have to be vigilant and make sure that classes with pointer data members don't rely on the default assignment behavior.
One other common pitfall with the assignment behavior is when we assign an object to itself.
If we want to prevent our assignment operator from allowing assignment to and from the same object, we can compare against the object's memory address as such:
ClassName& ClassName::operator= (const ClassName& other) {
// if the lvalue's address is not the same as the
// rvalue's address... (i.e. they are different objects)
if (this != &other) {
// ...assignment behavior here, safe from
// self-assignment
}
}
Summary
So, on the long journey from copy constructors to assignment overloading, here's a brief rundown:
Beware of copied pointers in the default copy constructor and default assignment behavior!
Beware of memory leaks from the assignment overloading!
Beware of dangling pointers from the assignment overloading!
To pull it all together, let's examine the following class that does a bunch of output to the console whenever key events happen:
#include <iostream>
#include <string>
using namespace std;
class NoisyClass {
private:
string s;
public:
NoisyClass () {
cout << "[C] Default constructor" << endl;
}
NoisyClass (string stuff) {
s = stuff;
cout << "[P] Parameterized constructor" << endl;
}
NoisyClass (const NoisyClass& other) {
s = other.s;
cout << "[~] Copy constructor" << endl;
}
~NoisyClass () {
cout << "[D] Destructor" << endl;
}
NoisyClass& operator= (const NoisyClass& other) {
s = other.s;
cout << "[=] Assignment" << endl;
return *this;
}
};
With the NoisyClass definition from above, what will the following code print out?
int main () {
NoisyClass n1,
n2;
n1 = n2;
// Don't forget that n1 and n2 are local...
}
With the NoisyClass definition from above, what will the following code print out?
int main () {
NoisyClass n1("Not the parameterized constructor >_> <_<");
NoisyClass n2(n1);
NoisyClass n3 = n2;
}
With the NoisyClass definition from above, what will the following code print out?
int main () {
NoisyClass* n1;
NoisyClass n2,
n3;
n1 = new NoisyClass();
n2 = *n1;
delete n1;
n3 = n2;
}
With the NoisyClass definition from above, what will the following code print out?
int main () {
NoisyClass n[3];
}
With the NoisyClass definition from above, what will the following code print out?
int main () {
NoisyClass* n;
n = new NoisyClass[4];
delete[] n;
}
Homework 1 Tips
DUE: Tuesday, January 20, 9:00 pm
A couple things to look out for on Homework 1 that may doom you:
Although your code may still work, superfluous include directives may cost you points! Make sure that you include only what is necessary to include in each header.
Remember to test compilation under multiple compilers!
Are capital letters contiguous is every character coding schema? Make sure to account for this...
Include guards!
Comments!
First, you've been reading through a lot of my notes, which must be draining without me there to say them to you.
To provide some morale support, here's an XKCD from a bit ago that reminded me of office hours:

Now, on the homework, you're asked to use typedef:
A typedef keyword simply provides a top-level new name (alias) for an existing type.
Uhh, OK... why do we need to use this?
Well, if we want our code to be able to handle different types, but don't want users to have to find and replace every instance of a particular type in our code, we can provide a typedef to do the work for them!
// typedef syntax: // typedef <ExistingType> <NewTypeName>; // ... so for example ... typedef int CRAZY_INT_NAME_WOW; CRAZY_INT_NAME_WOW i = 1, j = 2; cout << i + j << endl;
Finally, some general reminders:
Comments!
Read the spec description for the
getmember functions very carefully...Pay attention to the last sentence of criteria #4...
Test your code! The general strategy for testing is that you should try to find some combination of legal statements that actually break it!