Introduction to Resource Management
As you might have already seen in class, one of the interesting aspects of programming is that different problem solutions (although eliciting the same correct behavior), may go about finding the solution in wildly different ways.
The next thing you'll notice is that not all solutions are the same quality!
What I mean by this is that what one solution takes 2 minutes to solve, another takes 2 days...
Just because they arrive at the same answer, doesn't mean that one of them wasn't incredibly stupid in doing it.
Resource management involves the ability to effectively, efficiently, and economically use data structures to accomplish your program's goals.
That sounded more like a business slogan than a definition, but the idea is that you want to use the right tool for the right job, and then effectively clean up after ourselves.
So, let's examine how to engineer the right tools so we won't be sad.
Singly Linked Lists
Here's what we've said so far about Singly Linked Lists...
They are an abstract data type consisting of Nodes with data elements and a pointer to each successive Node:
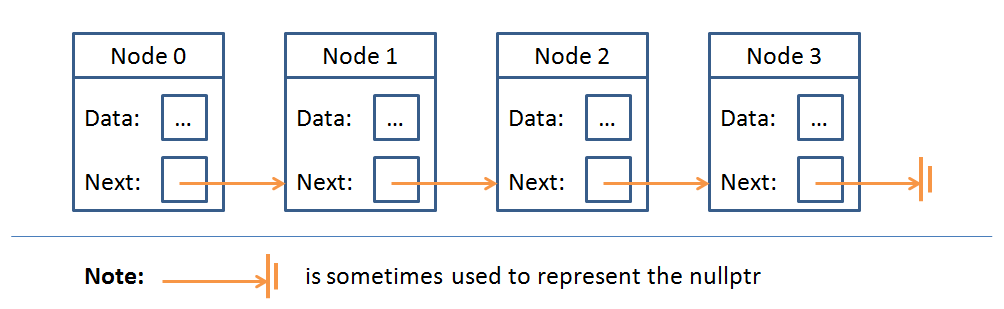
Then, we examined LinkedLists in comparison the Arrays because of their similarities. We concluded that, although they can do (mostly) the same things, Arrays are more efficient than LinkedLists at some things, and vice versa.
Element Insertion
We saw that adding elements to the end of an array is easy:
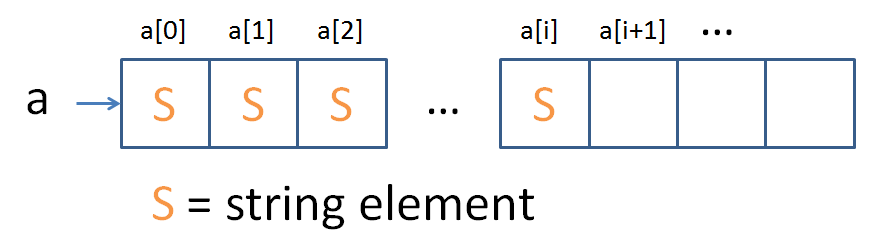
But finding the end of a LinkedList actually takes some effort:
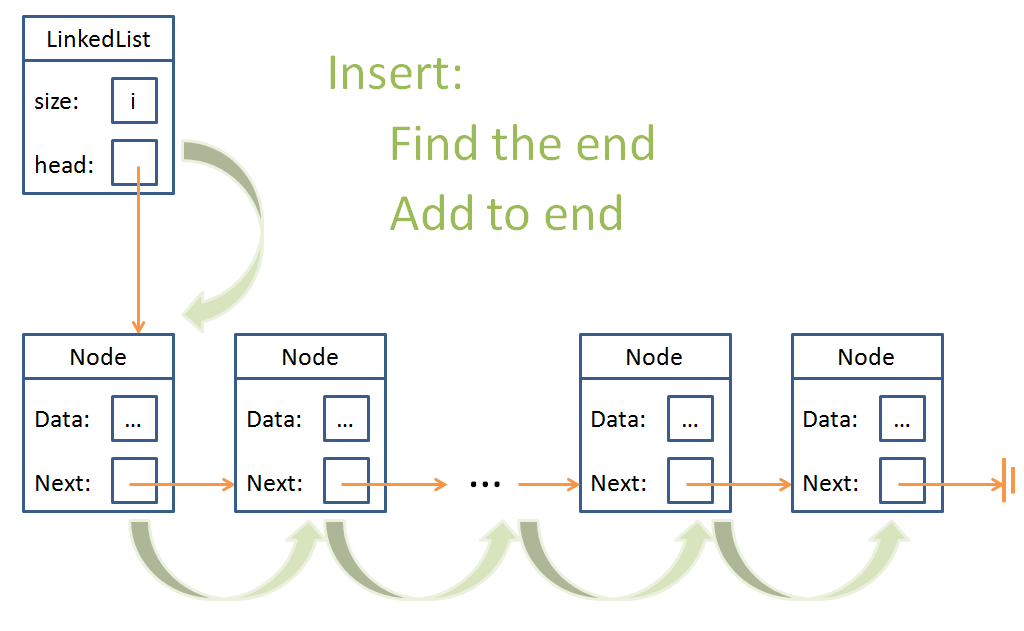
Now, we stopped the discussion there... that Arrays win at end-of-list insertions...
Is there a way that we could make LinkedLists comparable to Arrays with end-of-list insertion?
Yes! Maintain a pointer within the LinkedList that always points to the last Node. Let's call that the tail.
Here is a simple LinkedList class... why don't we modify it and see how we can improve the code?
// LinkedList.h
#ifndef LINKED_LIST_INCLUDED
#define LINKED_LIST_INCLUDED
#include <string>
#include <iostream>
class LinkedList {
private:
struct Node {
std::string m_data;
Node* m_next;
Node (std::string s) {
m_data = s;
m_next = nullptr;
}
};
Node* head;
// [!] Added the tail pointer
Node* tail;
int size;
public:
LinkedList();
~LinkedList();
void insert(std::string);
bool erase(std::string);
bool contains(std::string s);
void print();
};
#endif
// LinkedList.cpp
#include "LinkedList.h"
// Default LinkedList constructor
LinkedList::LinkedList () {
head = nullptr;
tail = nullptr;
size = 0;
}
// Destructor
LinkedList::~LinkedList () {
// TODO
}
We then looked at how to implement the insert to end function, and came up with the following:
// Insert a new Node at the end of the List
// with the given string data
void LinkedList::insert (std::string s) {
// 1) Dynamically allocate a Node
Node* toAdd = new Node(s);
// 2) Update the head if first insertion
if (head == nullptr) {
head = toAdd;
} else {
// 3) Make an iterator to find the last
// position in the List
Node* iterator = head;
// 4) Stick the new Node on the end of the List
while ( iterator->m_next != nullptr ) {
iterator = iterator->m_next;
}
iterator->m_next = toAdd;
}
// 5) Add one to the size
size++;
}
Modify the code for the insert function so that it uses and maintains the tail pointer:
// Insert a new Node at the end of the List
// with the given string data
void LinkedList::insert (std::string s) {
// 1) Dynamically allocate a Node
Node* toAdd = new Node(s);
// 2) Update the head if first insertion
if (head == nullptr) {
head = toAdd;
}
// 3) Make last node point to toAdd
// if the last node exists
// [!] ???
// 4) Tail now points to toAdd
// [!] ???
// 5) Add one to the size
size++;
}
Element Deletion
As another brief review, we saw that, for Arrays, element deletion is easy when we don't care about sorting the elements:
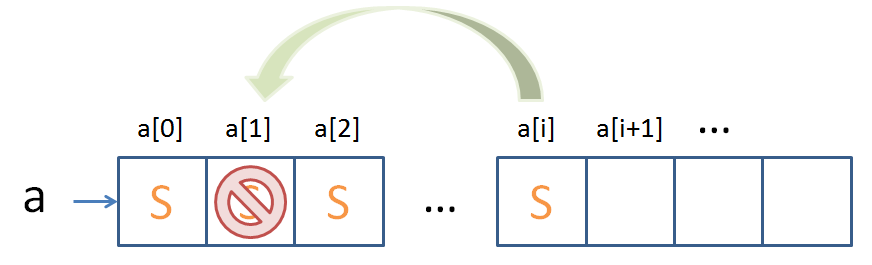
...but is actually a huge pain when we need to delete something toward the front / in the middle of the array:
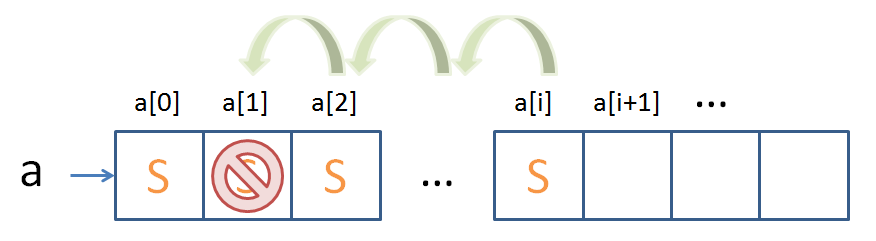
Lastly, we saw that LinkedLists perform admirably at deletion, but the overhead of finding the element to delete costs us efficiency:
[!] We will skip this section in class -- please read on your own!
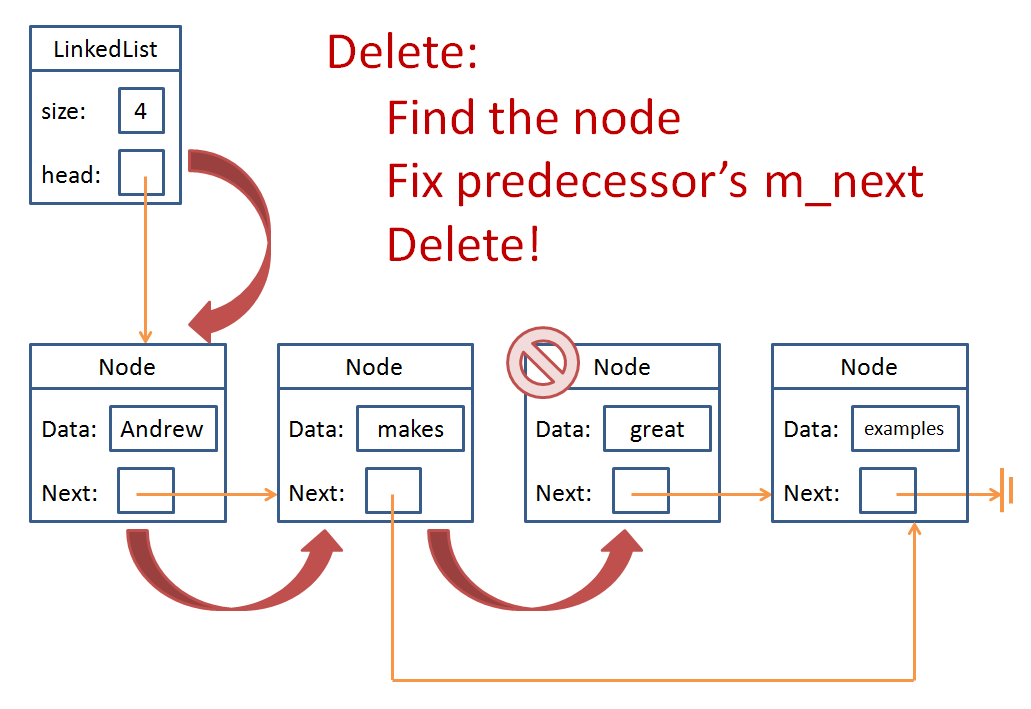
Let's look at the Singly Linked List delete for a moment...
Some poor soul on an internet forum submitted the following as a solution to a Singly Linked List deletion. Where does it go wrong?
bool LinkedList::erase (std::string s) {
Node* iterator = head;
Node* prev = nullptr;
bool erased = false;
// First, find the Node to delete...
while (iterator != nullptr) {
// If we don't find a match, keep looking
if (iterator->m_data != s) {
prev = iterator;
iterator = iterator->m_next;
// Otherwise, perform the necessary deletion
} else {
prev->m_next = iterator->m_next;
delete iterator;
erased = true;
break;
}
}
// Return whether or not we found
// and erased anything
return erased;
}
Practice & Diagnosis
Just to round everything out, let's do a little LinkedList triage and then move on (I totally didn't reuse these from Wednesday >_>):
Noob R. Nooberson thought that the following destructor would work for the LinkedList. Is there a problem with it?
// Destructor
LinkedList::~LinkedList () {
delete head;
}
Then, your illustrious TA suggested it would be cute to solve the above problem by doing the following; why is he a lamo?:
// ...
~Node () {
delete m_next;
}
// ...
Lord Voldemort himself produced the following attempt at the LinkedList contains function. Why should he not be named (in respectable programming circles)?
bool LinkedList::contains (std::string s) {
Node* iterator = head;
while (iterator->m_data != s && iterator != nullptr) {
iterator = iterator->m_next;
}
return iterator != nullptr;
}
He then tested it on this main function and concluded success:
#include "LinkedList.h"
int main () {
LinkedList listy;
listy.insert("WHERE");
listy.insert("IS");
listy.insert("POTTER");
std::cout << listy.contains("POTTER") << std::endl;
}
Application of Linked Lists: The Stack
Heretofore (can you believe that's a word?), we've only seen some abstract uses for LinkedLists and their comparisons to Arrays...
Let's talk about a real-world data structure that works well with LinkedLists: the stack.
A stack is a data structure used to store elements in a way that the most recently stored items are the first to be retrieved.
...O...K...
Trust me, it's cool! By analogy, think of a pile of dishes:
You stack dishes one on top of the other
Once you've stacked dish Z on top of all the other dishes, you can only access dish Z (and cannot access any other dish beneath it) until you pop Z off the top again
Stacks are very useful; in fact, there's a reason why local variables are stored in the stack, because every function's variables get stacked on the top when they're called, and popped off again when you leave the function!
So, let's try to use a LinkedList to represent this data structure:
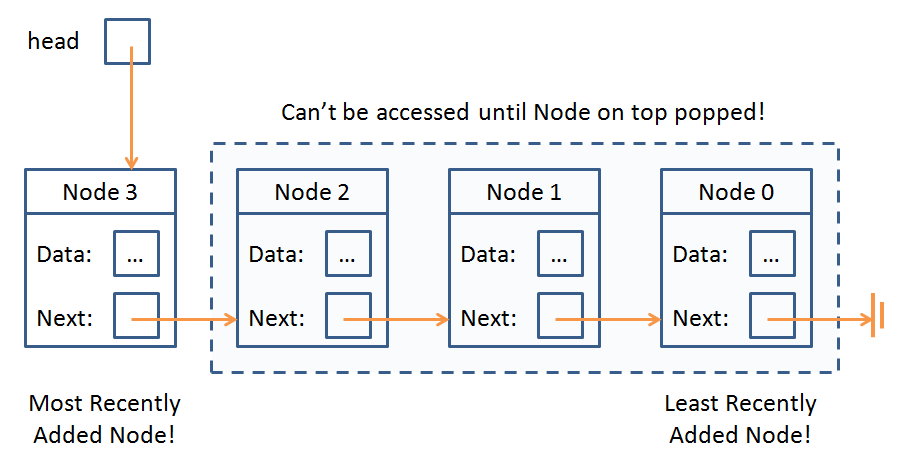
OK, Andrew, why would we want to make a data structure that's a LinkedList... but more restricted than one?
This goes back to our public vs. private interface discussion: we want to give users of our classes certain guaranteed behaviors that allow for predictable code execution. If an algorithm requires that only the most recently pushed Node can be accessed at any time, we need to make sure our users don't tamper with that guaranteed behavior.
Here's my new interface:
// Stack.h
#ifndef STACK_INCLUDED
#define STACK_INCLUDED
#include <string>
#include <iostream>
class Stack {
private:
struct Node {
std::string m_data;
Node* m_next;
Node (std::string s) {
m_data = s;
m_next = nullptr;
}
};
Node* head;
int size;
public:
Stack();
~Stack();
void push(std::string s);
std::string pop();
void print();
};
#endif
And, of course, a shell for the implementation.
// Stack.cpp
#include "Stack.h"
// Default Stack constructor
Stack::Stack () {
head = nullptr;
size = 0;
}
// Destructor
Stack::~Stack () {
// TODO
}
// Pushes a new Node with data string s
// to the top of the stack!
void Stack::push (std::string s) {
// TODO
}
// Pops the top Node on the stack off,
// returning its data member and removing
// itself from the top (making the one beneath
// it the new top)
std::string Stack::pop () {
// TODO
return "";
}
// ... print function same as for LinkedList
Let's fill out the push and pop functions to see it in action:
Implement the following shell for the push function:
// Pushes a new Node with data string s
// to the top of the stack!
void Stack::push (std::string s) {
// 1) Dynamically allocate a new Node
Node* toAdd = new Node(s);
// 2) The new node now points to the
// current head
// [!] Fill in here!
// 3) Whether it's first or not, have the head point
// to the new node
// [!] Fill in here!
// 4) Bump the size
size++;
}
If we test our push with the following main function, what gets printed out?
int main () {
Stack onStacksOnStacks;
onStacksOnStacks.push("Bill");
onStacksOnStacks.push("Dolla");
onStacksOnStacks.push("Dolla");
onStacksOnStacks.print();
}
[!] We will skip this section in class -- please read on your own!
Implement the following shell for the pop function:
// Pops the top Node on the stack off,
// returning its data member and removing
// itself from the top (making the one beneath
// it the new top)
std::string Stack::pop () {
// 1) Return the empty string if empty
if (head == nullptr) {
return "";
}
// 2) Set a pointer to the top node
// [!] Fill in here!
// 3) Save the top Node's data
std::string result; // [!] Fill in here!
// 4) Adjust head accordingly
// [!] Fill in here!
// 5) ...take care of the top Node... quietly...
// [!] Fill in here!
// 6) Reduce size
size--;
return result;
}
If we test our pop with the following main function, what gets printed out?
int main () {
Stack onStacksOnStacks;
onStacksOnStacks.pop();
onStacksOnStacks.push("TA");
onStacksOnStacks.push("great");
onStacksOnStacks.pop();
onStacksOnStacks.push("is a");
onStacksOnStacks.push("Andrew");
onStacksOnStacks.push("Great...");
onStacksOnStacks.print();
}
-_______________-
Doubly Linked Lists
[!] We will skip this section in class -- please read on your own!
Wake up your neighbors folks, let's talk Doubly Linked Lists.
A doubly linked list is just like a regular linked list, except each Node has a pointer to the previous Node in the sequence along with a pointer to the next Node.
What's this look like you ask?
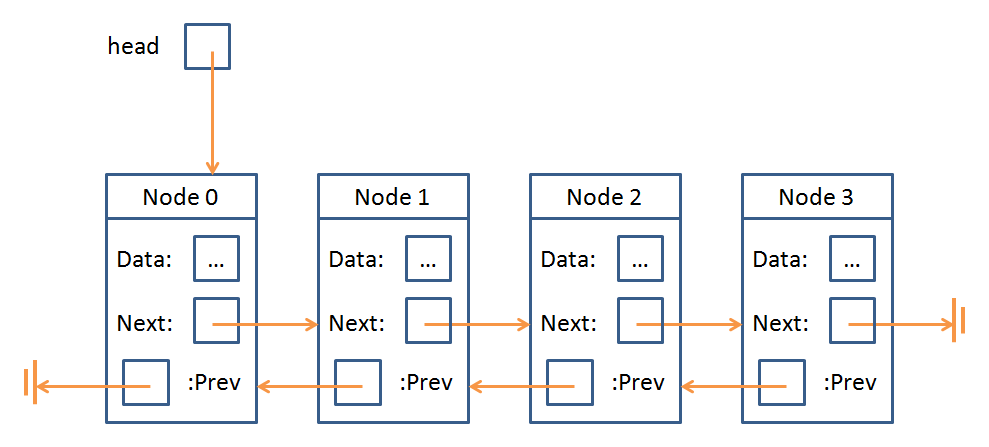
"I like the new arrows, Andrew... what good do they do?"
Excellent question. Whereas previously, in the Singly Linked List, we had only forward arrows, if we ever wanted information about a Node behind us in the sequence, we had to start all over at the beginning... now we don't!
I'm sure the 1 or 2 cases in which these new arrows save us headaches will more than make up for their upkeep...
Should we start at the start? Check out pushing elements to the end?
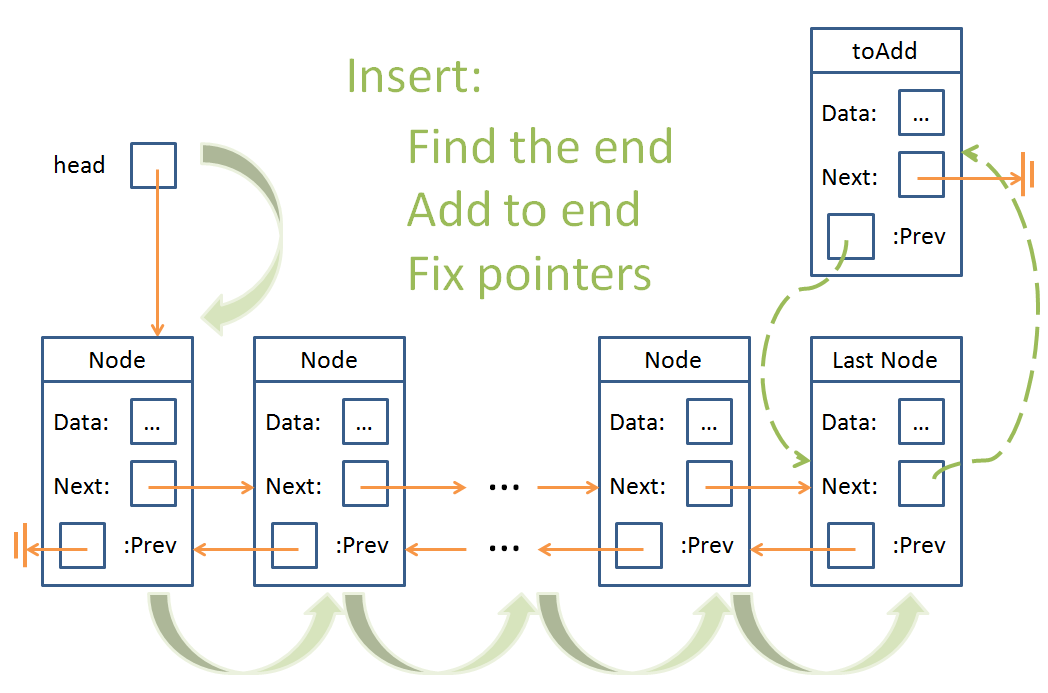
Alright... so we've been dealing with Nodes this whole time, but you know what?
I'm bored with Nodes... let's use a more pop-culture-friendly class and implementation.
// HumanCentipede.h
#ifndef HC_INCLUDED
#define HC_INCLUDED
#include <string>
#include <iostream>
class HumanCentipede {
private:
struct Person {
std::string m_data;
Person* m_front;
Person* m_behind;
Person (std::string s) {
m_data = s;
m_front = nullptr;
m_behind = nullptr;
}
};
Person* head;
Person* tail;
int size;
public:
HumanCentipede();
~HumanCentipede();
void insert(std::string);
bool erase(std::string);
void print();
};
#endif
...and if you haven't seen the movie, or didn't catch the reference, please don't look it up (read: please don't sue me if you do)
Make a single change to our LinkedList insert function to bring it up to speed with the HumanCentipede. That rhymed:
// Add a new person to the centipede at the
// end with name s
void HumanCentipede::insert (std::string s) {
// 1) Dynamically allocate a Person
// ...whatever that translates to in
// people terms...
Person* toAdd = new Person(s);
// 2) Update the head if first victim
if (head == nullptr) {
head = toAdd;
// 2) Otherwise, we already have some People
} else {
// TODO: Use tail in HumanCentipede to track
// the last slot in the centipede instead
// Make an iterator to find the last
// Person in the Centipede
Person* iterator = head;
// Stick the new Person on the end of the
// centipede
while ( iterator->m_front != nullptr ) {
iterator = iterator->m_front;
}
// Update the last Person's m_front
iterator->m_front = toAdd;
// Update the new Person's m_back
// [!] Fill in here!
}
// 3) Add one to the size
size++;
}
It should work with this main function:
int main () {
// Looked up the character names
HumanCentipede cent;
cent.insert("Katsuro");
cent.insert("Lindsay");
cent.insert("Jenny");
cent.print();
}
Alright, that one was basically a freebie... no more freebies for HumanCentipede... instead, let's just walk through the erase function.
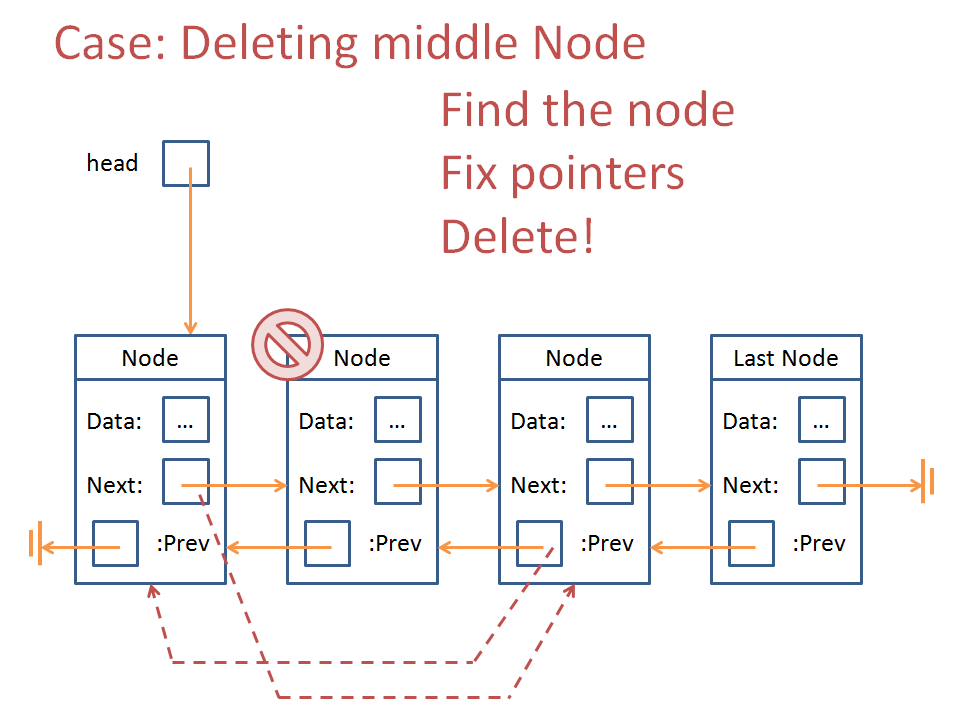
Here are some behaviors for erasing a node at certain positions in a Doubly Linked... err... HumanCentipede:
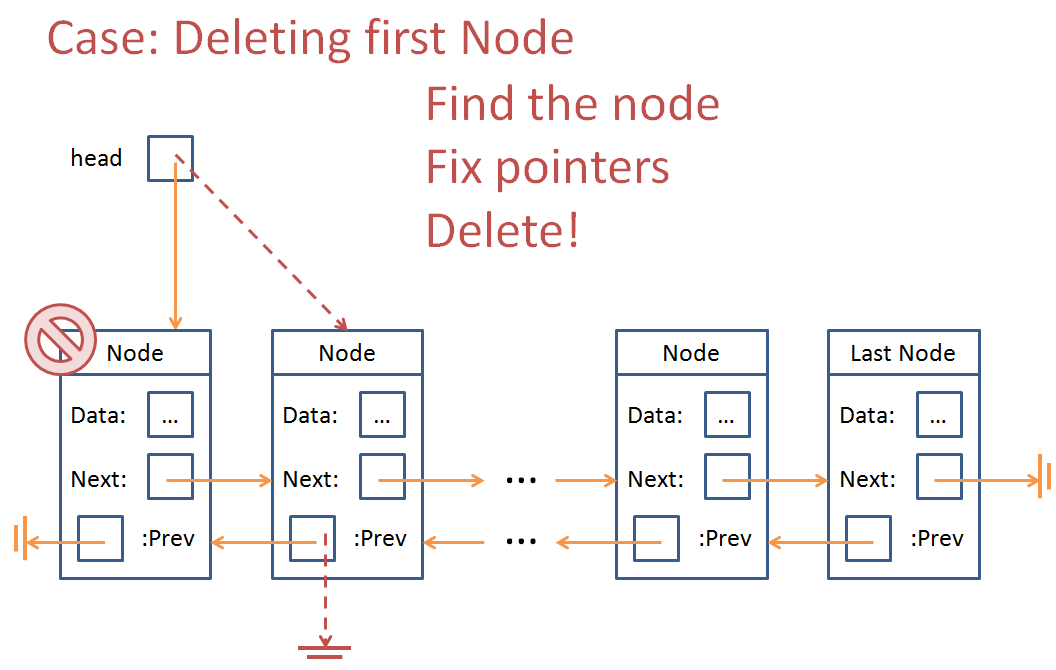
K, how about this one?
Queueueueueues
Queues aren't a whole lot different from stacks, except that instead of pushing to and popping from the top, we queue to the back of the queue and dequeue from the front.
A queue is another abstract data type that maintains the FIFO (first in, first out) behavior of insertion and retrieval of its elements.
Here's what that might look like as a singly linked list:
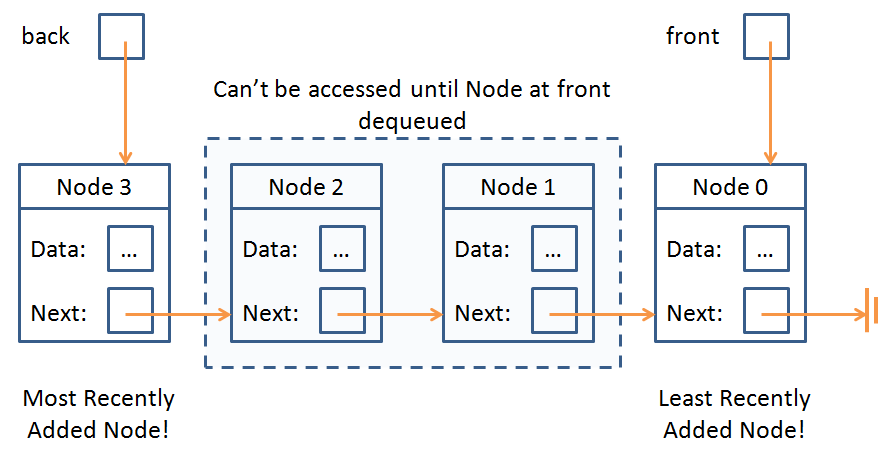
Again, though, you should be aware that a queue is an abstract data type, and that some implementations WILL allow you to access the intermediary nodes behind the front.
That, however, is not true of the C++ STL queue, which only has access to the front and back element.
Common Queue Functions:
push(element) (sometimes called enqueue) adds an element to the back of the queue.
pop() (sometimes called dequeue) removes the element from the front of the queue.
back() returns a reference to the element at the back of the queue (most recently added)
empty() returns true if the queue has no elements, false otherwise
size() returns a count of the number of elements in the queue
We'll talk about the STL queue in a future lecture.
Class Inheritance
Last week was unfortunately... quite dull... can we do something vaguely resembling entertainment?
Yeah I wish so too... unfortunately, all I have is the following:
I'm glad you guys are here because I'm designing an all new battle game that in no way, shape, or form resembles a certain Nintendo franchise...
Naturally, I'm calling it ForneyMon, where we have different mythical pets of different types locked in psuedo-humane combat for our amusement!
I'm starting off slow and hoping we can develop the concept a bit in this class... here's the gist:
I have two types of ForneyMon right now: the BurnyMon, which singes its opponents with the fire of 5 suns, and DampyMon, which annoys its opponents by getting them wet.
Both have a certain amount of starting health and a name that its trainer err... owner has given it.
Presently, ForneyMon can only interact by dealing damage and taking damage of a certain type (e.g. Burny damage or Dampy damage).
DampyMon take bonus damage from BurnyMon, but DampyMon start with more health.
...anyways here's the sketch I have so far, take a look:
#include <iostream>
#include <string>
using namespace std;
class DampyMon;
class BurnyMon {
private:
string m_name;
int m_health;
public:
BurnyMon (string name);
int takeDamage (int dam, string type);
void dealDamage (DampyMon* other, int dam, string type);
};
class DampyMon {
private:
string m_name;
int m_health;
public:
DampyMon (string name);
int takeDamage (int dam, string type);
void dealDamage (BurnyMon* other, int dam, string type);
};
Point out some problems with my class definitions (and don't you dare say the whole example).
No ability to talk about groups of ForneyMon, regardless of whether they're DampyMon or BurnyMon
Code repetition, especially with private members and constructors
No scalability: all of my functions that target other ForneyMon are specific to the class of the other ForneyMon!
Let's look at each of these problems separately and see how we might fix them:
Abstracting Common Members
As we noticed, the private members for our two classes are the same!
Remind me, why is code repetition bad?
It violates the One-Change, One-Place principal, wastes file space, and can potentially hinder efficiency.
If we could somehow abstract those elements outside of these two classes into another class that, say, was higher in a hierarchy, that would be great!
Turns out, that's exactly what we'll do...
A base class is a class from which other (derived) classes inherit properties.
We'll define a base class from which our two classes inherit some common elements. This makes our two classes that inherit from the base class called derived classes.
A derived class is a class that inherits features from a base class.
Inheritance, therefore, is the process of defining a derived class from an existing base class. We say that the derived class inherits certain characteristics of its base.
The syntax for defining inheritance is the following:
class DerivedClass: public BaseClass {
// ...
};
Here's a simple example of inheritance of a Base class to a Derived class:
struct DropTheBase {
int a;
string s;
string m;
DropTheBase () {
a = 3;
s = "[s] Base!";
m = "[m] Base!";
}
};
// These puns are almost cringey... almost
struct DerivingMeCrazy : public DropTheBase {
int a;
string s;
string t;
DerivingMeCrazy () {
a = 1;
s = "[s] Derived!";
t = "[t] Derived!";
}
};
So what's happening behind the scenes here? Let's look at a few properties of inheritance:
The is-a relationship describes the inheritance flow from a base class to a derived class. We say that a derived class is-a type of the base class.
Well, during lecture, we said that a Dog (derived class) is-a Mammal (base class).
So, above, we say that DerivingMeCrazy is-a DropTheBase... hmm, not one of my finest examples... but worth the joke.
What this means is that the Base class, and all of its members, are now a PART of the derived class!
The UML standard for representing inheritance is by drawing an arrow from the Derived classes to their Base class(es); I've also represented our inheritance from a sort of... member perspective:
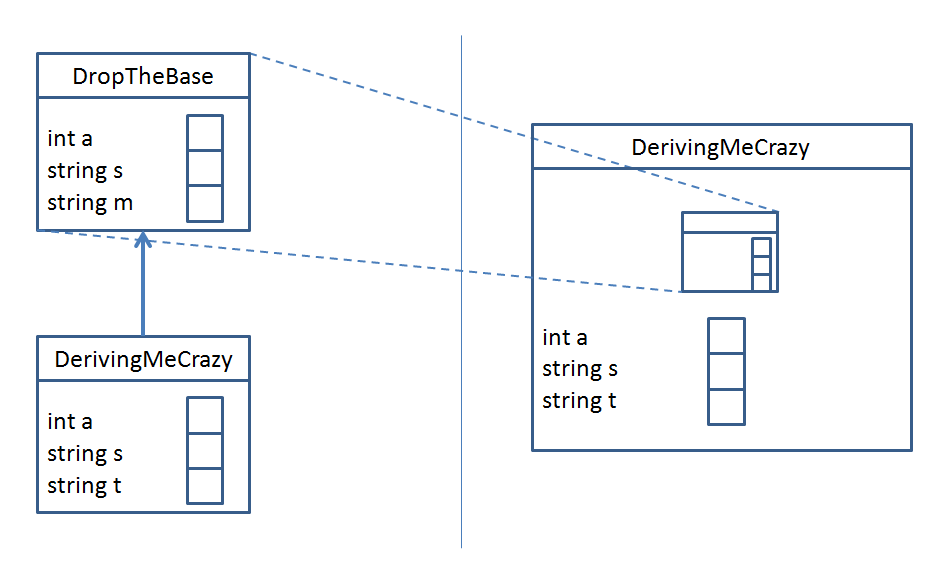
See how that relationship works out?
This means that I can access any (public or equally visible) member of a Base class from its Derived classes.
See how we access the m member from a DerivingMeCrazy class:
struct DropTheBase {
int a;
string s;
string m;
DropTheBase () {
a = 3;
s = "[s] Base!";
m = "[m] Base!";
}
};
struct DerivingMeCrazy : public DropTheBase {
int a;
string s;
string t;
DerivingMeCrazy () {
a = 1;
s = "[s] Derived!";
t = "[t] Derived!";
}
};
int main () {
DerivingMeCrazy d;
cout << d.a << endl;
cout << d.s << endl;
cout << d.t << endl;
cout << d.m << endl;
}
Now that's all fine and good, but why did I get the Derived class versions of a and s
over the DropTheBase versions?
If a data member is defined in both a Derived class and its Base class, AND:
An object is an instance of the Derived class, then we use the Derived class' definitions of those members.
An object is an instance of the Base class, then we use the Base class' definitions of those members.
So, if I have a DropTheBase object, I use the Base class' a and s...
So, if I have a DerivingMeCrazy object, I use the Derived class' a and s...
If a member is not defined in my object's class, I will try to find it in my Base classes.
What will the following code print out?
struct DropTheBase {
int a;
string s;
string m;
DropTheBase () {
a = 3;
s = "[s] Base!";
m = "[m] Base!";
}
};
struct DerivingMeCrazy : public DropTheBase {
int a;
string s;
string t;
DerivingMeCrazy () {
a = 1;
s = "[s] Derived!";
t = "[t] Derived!";
}
};
int main () {
DropTheBase b;
DerivingMeCrazy d;
cout << d.a << endl;
cout << b.a << endl;
cout << d.s << endl;
cout << b.s << endl;
cout << d.m << endl;
cout << b.m << endl;
}
Will any of the following lines of code need to be removed to allow it to compile? If so, which of the numbered lines, and what will it print out once they're removed?
struct Basically {
int a;
int b;
Basically () {a = 1; b = 2;}
};
struct Best : public Basically {
int a;
int c;
Best () {a = 3; c = 4;}
};
struct Example : public Basically {
int a;
int d;
Example () {a = 5; d = 6;}
};
int main () {
Basically base;
Best best;
Example ex;
cout << base.a << endl; // 1
cout << best.a << endl; // 2
cout << ex.a << endl; // 3
cout << best.b << endl; // 4
cout << ex.c << endl; // 5
cout << ex.d << endl; // 6
cout << base.d << endl; // 7
}
Draw a UML-like inheritance diagram and show what classes are a "part" of the others.
Will any of the following lines of code need to be removed to allow it to compile? If so, which of the numbered lines, and what will it print out once they're removed?
struct Basically {
int a;
int b;
Basically () {a = 1; b = 2;}
};
struct Best : public Basically {
int a;
int c;
Best () {a = 3; c = 4;}
};
// [!] Note the inheritance change!
struct Example : public Best {
int a;
int d;
Example () {a = 5; d = 6;}
};
int main () {
Basically base;
Best best;
Example ex;
cout << base.a << endl; // 1
cout << best.a << endl; // 2
cout << ex.a << endl; // 3
cout << best.b << endl; // 4
cout << ex.c << endl; // 5
cout << ex.d << endl; // 6
cout << base.d << endl; // 7
}
Draw a UML-like inheritance diagram and show what classes are a "part" of the others.
Now, here comes the magic...
I know that because DerivingMeCrazy inherits from DropTheBase, which means that somewhere in DerivingMeCrazy is a DropTheBase object... how do I access its members?
If I have a pointer of type Base class, and it points to an object of one that Base class' Derived classes, then my pointer now points to the Base class portion of that Derived class object.
Here's what that looks like:
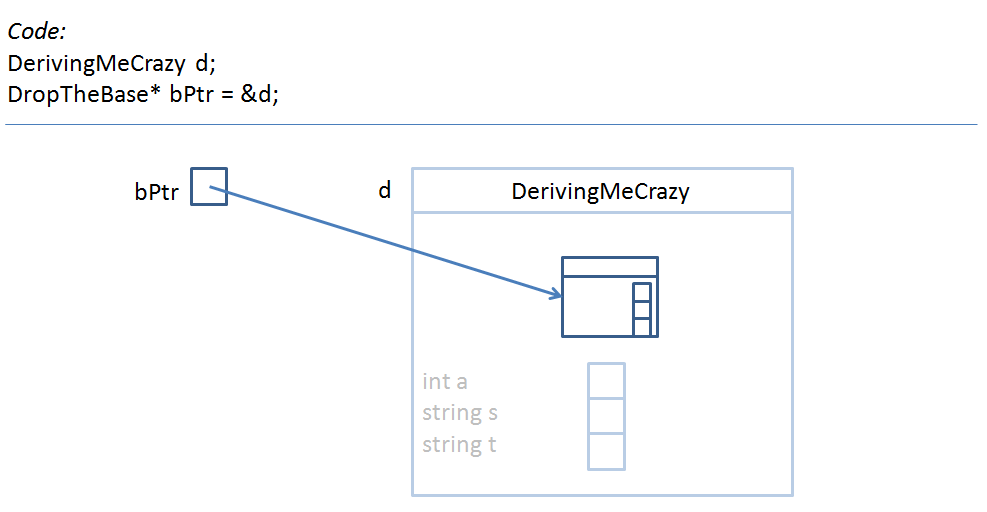
So knowing that's how pointers of the Base class behave, what will the following print out?
struct DropTheBase {
int a;
string s;
string m;
DropTheBase () {
a = 3;
s = "[s] Base!";
m = "[m] Base!";
}
};
struct DerivingMeCrazy : public DropTheBase {
int a;
string s;
string t;
DerivingMeCrazy () {
a = 1;
s = "[s] Derived!";
t = "[t] Derived!";
}
};
int main () {
DerivingMeCrazy d;
DropTheBase* bPtr = &d;
cout << bPtr->a << endl;
cout << bPtr->s << endl;
cout << bPtr->m << endl;
}
NOTE: I said that a Base class pointer can point to the Base class portion of one of its Derived class' objects... it does NOT work the other way around.
Will the following code compile?
int main () {
DropTheBase b;
DerivingMeCrazy* dPtr = &b;
cout << dPtr->s << endl;
}
Will the following code compile? If so, what will it print out?
int main () {
DropTheBase b = DerivingMeCrazy();
cout << b.a << endl;
cout << b.s << endl;
cout << b.m << endl;
}
Will the following code compile? If so, what will it print out?
int main () {
DerivingMeCrazy b = DropTheBase();
cout << b.a << endl;
cout << b.s << endl;
cout << b.m << endl;
}
Heterogeneous Collections
One of the issues we noticed was that I cannot make a collection (let's say, an array) of ForneyMon that consists of both BurnyMon and DampyMon.
It would be nice if I could tell the compiler that I want to make a sort of type hierarchy where I arrange both of these classes under a more general one...
Hey, how bout that! Turns out I can...
So, let's start by defining a new base class called ForneyMon:
Have the BurnyMon and DampyMon classes inherit from a new ForneyMon base class, which you'll define. Abstract the m_name and m_health members into ForneyMon.
class ForneyMon {
private:
// [!] Need to add members
public:
ForneyMon (string n, int h);
};
// [!] Need to change something here
class BurnyMon {
private:
// [!] Need to change something here
string m_name;
int m_health;
public:
BurnyMon (string name);
int takeDamage (int dam, string type);
// [!] Need to change something here
void dealDamage (DampyMon* other, int dam, string type);
};
// [!] Need to change something here
class DampyMon {
private:
// [!] Need to change something here
string m_name;
int m_health;
public:
DampyMon (string name);
int takeDamage (int dam, string type);
// [!] Need to change something here
void dealDamage (BurnyMon* other, int dam, string type);
};
Now, all that we're missing is a way to construct our objects and we'll be on our way!
Let's look at how to do that next...
Hey Look, More on Construction
Before we can implement our constructors for the ForneyMon, BurnyMon, and DampyMon classes, we'll need to see all of the construction steps:
Construct this class' base class(es)
Construct this class' data members
Execute the body of the constructor
Let's look at each step and then integrate them into our ForneyMon implementation.
We construct the base class of the object we're constructing before we do anything else.
Although the base class is not technically a member of the derived class, we construct it using the member initialization list of the derived class.
So, let's look at how that constructor might look for some inheritance structure:
What will the following code print out?
// Ugh this joke is bad...
struct AllYourBase {
string stuff;
AllYourBase (string s) {
cout << "[Base] Constructor!" << endl;
stuff = s;
}
};
struct AreBelongToUs : public AllYourBase {
int i;
AreBelongToUs (string s, int j) : AllYourBase(s) {
cout << "[Derived] Constructor!" << endl;
i = j;
}
};
int main () {
AreBelongToUs a(":D", 3);
cout << a.i << endl;
cout << a.stuff << endl;
}
Will the following code compile? If so, what will it print out?
struct AllYourBase {
string stuff;
AllYourBase (string s) {
cout << "[Base] Constructor!" << endl;
stuff = s;
}
};
struct AreBelongToUs : public AllYourBase {
int i;
// [!] Member initialization of base class removed
AreBelongToUs (string s, int j) {
cout << "[Derived] Constructor!" << endl;
i = j;
}
};
int main () {
AreBelongToUs a(":D", 3);
cout << a.i << endl;
cout << a.stuff << endl;
}
Now that we know how construction works, let's implement our constructors for ForneyMon!
Here's what I want of each ForneyMon constructor:
Each ForneyMon will be given a name
Health is decided by the type of ForneyMon; a BurnyMon will start with 10 health, and a DampyMon with 15.
// [!] ForneyMon Constructor
ForneyMon::ForneyMon (string n, int h) {
m_name = n;
m_health = h;
}
// [!] Initialization list constructing Base Class
// components of each BurnyMon and DampyMon
BurnyMon::BurnyMon (string n) : ForneyMon(n, 10) {}
DampyMon::DampyMon (string n) : ForneyMon(n, 15) {}
Returning to our heterogeneous collections example, and assuming we did the above correctly, I can now say things like:
int main () {
ForneyMon* menagere[3];
menagere[0] = new BurnyMon("Emberliz");
menagere[1] = new DampyMon("Blastoilet");
// Now with double the copyright infringement!
menagere[2] = new BurnyMon("Firefox");
}
See how I was able to store pointers to (the base class components of) both BurneyMon and DampyMon in that array?! Crazy!
But why is this useful if all I can ever access are the common ForneyMon elements of each?
Let's find out!
Polymorphism
Polymorphism is defined as "the provision of a single interface to entities of different types."
Ugh... let's unpack that:
We have two different types: BurnyMon and DampyMon, and each of them can take damage (i.e., they each have a takeDamage function, the single interface), but the way each handles taking damage is slightly different.
We know that pointers of polymorphic Base classes are type-compatible with objects of their Derived classes...
If we have a ForneyMon pointer to a BurnyMon object vs a ForneyMon pointer to a DampyMon object, do we want each pointer's member function calls to have the exact same behavior?
No! We've already said that some operations of DampyMon differ from those of BurnyMon.
So, let's see how to distinguish between member functions.
First off, some definitions and rules:
A function binding determines which function implementation in which class to call when that function name is overloaded.
Non-virtual member functions will bind to the implementation within the type of the object or pointer that called them (aka static-binding, the default).
What will the following code print out?
// Too good to just have in one example:
// (read: I'm too lazy to think of another)
struct AllYourBase {
void yell () {
cout << "[Base] AIEEE!" << endl;
}
};
struct AreBelongToUs : public AllYourBase {
void yell () {
cout << "[Derived] AIEEE!" << endl;
}
};
int main () {
AllYourBase base;
AreBelongToUs derived;
AllYourBase* basePtr = &derived;
base.yell();
derived.yell();
basePtr->yell();
}
Is it a problem that derived.yell(); and basePtr->yell(); elicited different behaviors?
Generally, yes; there would be no point to having base and derived classes if we couldn't have a Base class pointer to a Derived class that elicits the derived class' member function behavior. We'll look at how to solve that problem shortly.
If a function is not defined for a Derived class, but it is for the Base class, then we will use the Base class' implementation.
Will the following code compile? If so, what will it print out?
struct AllYourBase {
void yell () {
cout << "[Base] AIEEE!" << endl;
}
};
struct AreBelongToUs : public AllYourBase {
// >_> <_<
};
int main () {
AllYourBase base;
AreBelongToUs derived;
AllYourBase* basePtr = &derived;
base.yell();
derived.yell();
basePtr->yell();
}
You can call a base class' functions from inside a derived class by using the scope access (::) operator:
What will the following code print out?
struct AllYourBase {
void yell () {
cout << "[Base] AIEEE!" << endl;
}
};
struct AreBelongToUs : public AllYourBase {
void yell () {
AllYourBase::yell();
}
};
int main () {
AllYourBase base;
AreBelongToUs derived;
AllYourBase* basePtr = &derived;
base.yell();
derived.yell();
basePtr->yell();
}
Cool right? So knowing these three rules for non-virtual member functions, let's try implementing takeDamage and dealDamage for ForneyMons... ForneyMen? ForneyMon (plural and singular).
I want to define a general ForneyMon takeDamage and then specify any different behavior within the derived classes.
Since there's nothing special about how BurnyMon take damage, let's let the Base class handle that.
However, since I want special handling of how DampyMon take damage, we'll override its implementation.
// ...
class BurnyMon : public ForneyMon {
public:
BurnyMon (string name);
// [!] takeDamage removed from BurnyMon!
void dealDamage (ForneyMon* other, int dam, string type);
};
// ...
// (General) Take damage regardless of the type of attack
int ForneyMon::takeDamage (int dam, string type) {
// Reduce the current health by dam amount
m_health -= dam;
cout << "[" << type << "] Damage: -" << dam << endl;
return m_health;
}
// (DampyMon) Take damage equal to dam UNLESS the type
// of the attack was burny, in which case take 1 extra
int DampyMon::takeDamage (int dam, string type) {
if (type == "burny") {
dam += 1;
}
// [!] TODO: Note, I do not have access to the Base
// class' private members in derived class member
// functions! What to do, what to do?
return /* TODO ??? */;
}
If all went according to plan, I should see the following output -2 and -3 damage respectively:
int main () {
// Why do all my variables end with y?
// It's not even cute...
BurnyMon scorchy("Scorchy");
DampyMon puddly("Puddly");
// Damage working as intended!
scorchy.takeDamage(2, "dampy");
puddly.takeDamage(2, "burny");
}
But there's one problem left... what happens if I try the following?
int main () {
BurnyMon scorchy("Scorchy");
DampyMon puddly("Puddly");
ForneyMon* ptr = &puddly;
scorchy.takeDamage(2, "dampy");
// [!] Issue here:
ptr->takeDamage(2, "burny");
}
Uh oh, even though I had a ForneyMon pointer to a DampyMon, I still only took 2 damage from a burny attack... let's see how to fix this next!
Virtual Functions
We've already seen the behavior of static-binding such that we call the member function implementation within the class of the object, or pointer to object, that's calling it.
Static binding is decided at compile-time.
In the case where we want the function implementation of the Derived class that a Base class pointer points to, then we need dynamic-binding.
Dynamic binding is decided at runtime, and executes the Derived class function implementation of any overloaded Base class function tagged with the keyword
virtual.
That's a lot of noise, let's look at it in action:
What will the following code print out?
struct AllYourBase {
// [!] Note the virtual keyword
virtual void yell () {
cout << "[Base] AIEEE!" << endl;
}
};
struct AreBelongToUs : public AllYourBase {
virtual void yell () {
cout << "[Derived] AIEEE!" << endl;
}
};
int main () {
AllYourBase base;
AreBelongToUs derived;
AllYourBase* basePtr = &derived;
AreBelongToUs* derPtr = &derived;
base.yell();
derived.yell();
basePtr->yell();
derPtr->yell();
}
Woah, so basePtr knew to use the Derived class' implementation? Doesn't it just point to the Base object within the Derived one? How'd it know to use it?
Whenever we declare at least one member function of a Base class as virtual, it is considered a virtual class. It, and any of its derived classes, will establish virtual tables that are pointers to the correct function implementation to use for each context.
NOTE: I did NOT have to declare the AreBelongToUs::yell (); as virtual, though it is clean programming to do so in order to alert users that the overloaded function will be dynamically bound.
So, whenever I create an object with a Base class that has *at least one* virtual function, I create hidden pointers within the object stored in its virtual table.
A virtual table is just an array of pointers to virtual functions that point to the correct implementation at runtime.
We won't talk much about virtual tables, but know that they are hidden members that we, as programmers, don't interface with.
So let's return to the problem of our ForneyMon possibly having the wrong implementation of takeDamage called (when a ForneyMon pointer points to a DampyMon object and calls takeDamage).
I need make only one change to my ForneyMon class to elicit the desired behavior. What is it?
Simply declare ForneyMon::takeDamage to be virtual!
With this fix made, what does the following code print out?
int main () {
AllYourBase base;
AreBelongToUs derived;
AllYourBase* basePtr = &derived;
AreBelongToUs* derPtr = &derived;
base.yell();
derived.yell();
basePtr->yell();
derPtr->yell();
}
Sweet! Well that problem's resolved; here's a summary of what objects map to what function calls:
Pointer Type → |
Base Class Pointer |
Derived Class Pointer |
|---|---|---|
Base Class Object |
Base class function |
Error: cannot have derived class pointer to base class |
Derived Class Object |
[If base has virtual] Derived class function |
Derived class function |
Of course there's one last thing to consider with our ForneyMon...
Pure Virtual Functions
There's one thing left that we'll discuss about ForneyMon... take the following code for example:
int main () {
ForneyMon f("Forneytron", 2000);
f.takeDamage(0, "NOTHING HARMS FORNEYTRON");
}
Errr... I've created a ForneyMon... ForneyMon... that's not right, I only wanted to allow BurneyMon and DampyMon to be created!
Like we said in class, we should never be able to create a Mammal (base) object so much as a Dog (derived) object, because Mammal is just an archtype classification.
So, I want to find a way to prevent users from creating ForneyMon objects, because this class is meant to be abstract.
An abstract class is one in which at least one function is declared as pure-virtual. You cannot create objects of abstract classes.
Alright, so what's a pure virtual function?
A pure virtual function is denoted by placing "= 0" after the function signature, meaning that the class in which the signature exists is now an abstract class, and that all classes derived from it must either implement said function or become abstract themselves.
A pure virtual function can still be implemented, but need not be so.
Let's see how that looks...
Will the following code compile? If so, what will it output?
struct Basically {
int a;
int b;
Basically () {a = 1; b = 2;}
// [!] Pure virtual function
virtual int compute () = 0;
};
struct Best : public Basically {
int a;
int c;
Best () {a = 3; c = 4;}
virtual int compute () {return a + b;}
};
int main () {
Basically base;
Best best;
cout << best.compute() << endl;
}
Will the following code compile? If so, what will it output?
struct Basically {
int a;
int b;
Basically () {a = 1; b = 2;}
// [!] Pure virtual function
virtual int compute () = 0;
};
struct Best : public Basically {
int a;
int c;
Best () {a = 3; c = 4;}
virtual int compute () {return a + b;}
};
// [!] Added another class...
struct Example : public Best {
int a;
int d;
Example () {a = 5; d = 6;}
};
int main () {
Best best;
Example ex;
cout << ex.compute() << endl;
}
Very cool... so, let's look again at our ForneyMon classes:
class ForneyMon {
private:
string m_name;
int m_health;
public:
ForneyMon (string n, int h);
virtual int takeDamage (int dam, string type);
};
class BurnyMon : public ForneyMon {
public:
BurnyMon (string name);
// [!] Take damage removed from BurnyMon!
void dealDamage (ForneyMon* other, int dam, string type);
};
class DampyMon : public ForneyMon {
public:
DampyMon (string name);
int takeDamage (int dam, string type);
void dealDamage (ForneyMon* other, int dam, string type);
};
Is there a function I could make pure virtual so that my ForneyMon class becomes abstract?
Yes! The dealDamage function, which has the same signature for each derived class! Alternately, I could declare, and implement, a pure virtual destructor.
We'll need to implement the dealDamage function in our derived classes now that we declared in pure virtual in our base. Do so now!
// [!] Hmm, these are the same function! I probably should make
// this a function of ForneyMon instead... left as an exercise ;)
void BurnyMon::dealDamage (ForneyMon* other, int dam, string type) {
other->takeDamage(dam, type);
}
void DampyMon::dealDamage (ForneyMon* other, int dam, string type) {
other->takeDamage(dam, type);
}
As a final note, if I don't have any functions that I want to make pure virtual, but still want an abstract class, then I can define a pure virtual destructor for the base that I implement.
So, let's make that change now and see if our code behaves as intended...
If everything went according to plan, then the following code should *not* compile:
// [!] Warning: Should NOT compile if everything went well
int main () {
ForneyMon f("FORNEYTRON", 2000);
cout << f.takeDamage(0, "INVINCIBLLLE") << endl;
}
Alright! My ForneyMon classes are looking pretty good!
Now, let's abandon them forever!
Destructors & Virtual Destructors
There's a final concern with inheritance that we should consider: the clean up!
We know, of course, that this must involve the destructors.
As it turns out, the destruction process is simply the reverse of the construction one:
Execute the destructor body.
Destroy any remaining non-dynamic data members (built-in types are ignored)
Destroy the base part.
So, let's look back at our constructor example and add some dynamically allocated members:
struct AllYourBase {
// [!] New data member is pointer to
// dynamically allocated string!
string* stuff;
AllYourBase (string s) {
cout << "[Base] Constructor!" << endl;
stuff = new string(s);
}
~AllYourBase () {
cout << "[Base] Destructor!" << endl;
delete stuff;
}
};
struct AreBelongToUs : public AllYourBase {
// [!] New data member is pointer to
// dynamically allocated int array!
int* i;
AreBelongToUs (string s, int* j, int size) : AllYourBase(s) {
cout << "[Derived] Constructor!" << endl;
i = new int[size];
for (int k = 0; k < size; k++) {
i[k] = j[k];
}
}
~AreBelongToUs () {
cout << "[Derived] Destructor!" << endl;
delete[] i;
}
};
Remembering our steps of construction and destruction, will there be any memory leaks in the following code? What will it print out?
int main () {
int j[] = {1, 2, 3};
AreBelongToUs a(":D", j, 3);
}
Remembering our steps of construction and destruction, will there be any memory leaks in the following code? What will it print out?
int main () {
AllYourBase b("AIEE!!!");
}
Remembering our steps of construction and destruction, will there be any memory leaks in the following code? What will it print out?
int main () {
int j[] = {1, 2, 3};
AllYourBase* ptr = new AreBelongToUs(":(", j, 3);
delete ptr;
}
Ruh roh... I see I called my derived constructor (which performs dynamic allocation), but never my derived destructor! Memory leak! What happened?
Why didn't the derived destructor get called in the example above?
Because the base destructor is statically bound due to the pointer being of the Base type!
So, again, we rely on the virtual keyword to save the day by using virtual destructors to get dynamic binding.
A virtual destructor ensures that the proper object destructor is called at runtime, regardless of what type of pointer is having delete called on it.
So, to fix our error above, we simply add the virtual keyword to the Base class' destructor!
// ...
// [!] Now, destructor is virtual
virtual ~AllYourBase () {
cout << "[Base] Destructor!" << endl;
delete stuff;
}
// ...
So, let's revisit our problematic example and make sure that the dynamic binding is indeed happening:
int main () {
int j[] = {1, 2, 3};
AllYourBase* ptr = new AreBelongToUs(":(", j, 3);
delete ptr;
}
Whew! All clear!
So, we see that it's very dangerous to leave a base class without a virtual destructor, even if there are no dynamic members to clean up in the base class.
Rule: if a class is going to be a Base class, give it a virtual destructor, which means you must also implement it, even if the body is blank!
Implement a virtual destructor for the ForneyMon class.
That's it for inheritance and polymorphism... on to the fun stuff...
Project 2 Tips
Your task for the second project is to design a simple variant of a BASIC interpreter by managing a call stack that keeps track of where your program pointer is at all times.
Here's a simple program in the Facile programming language that you'll be defining:
// Line numbers added: 1. LET A 1 // Set var A to 1 2. GOSUB 7 // Push 2 onto call stack; go to line 7 3. PRINT A // Print value of A 4. END // End the program 5. LET A 3 // Set var A to 3 6. RETURN // Return to whatever line is at top of call stack 7. PRINT A // Print value of A 8. LET A 2 // Set var A to 2 9. GOSUB 5 // Push 9 onto call stack; go to line 7 10. PRINT A // Print value of A 11. RETURN // Return to whatever line is at top of call stack 12. . // End the program (and indicating no more code beyond this line)
What will the following code print out?
1 3 3
Before we talk about the GOSUB, you should be familiar with the call stack in C++, which we track every time a function is called (similar to our Facile's GOSUB command).
The call stack is the data structure that stores variables relevant to the active function, including, but not limited to: local variables, function parameters, and return addresses.
We talk a lot about the call stack and how it relates to functions, local variables, and scope in general, but only now are we equipped to view it in terms of a stack.
What we'll look at right now is a general, high-level picture of the call stack as we trace code through a couple arbitrary functions.
Remember that whenever we call a function, we go to the portion of the running machine code that corresponds to its code body.
But, when we leave the function that calls another function, we have to remember things like the local variables of the calling scope and where to return to when we're done with our call.
A stack frame consists of the function-specific variables and return addresses of a function call placed on the stack.
Check out this simple example:
string helpImStacked (int i, string s) {
// i and s pass-by-value copies
// that are local to function
string result;
for (int j = 0; j < i; j++) {
result += s + "\n";
}
// Need to know where to return to!
return result;
}
int main () {
// i and s local to main
int i = 5;
string s = "Is it 11:50 yet?";
// Push the helpImStacked stack frame
// onto the call stack
// [!] Save this point to be where I want
// to return to!
s = helpImStacked(i, s);
cout << s;
}
So, let's look at the call stack pictorially, with each function's stack frame color coded:
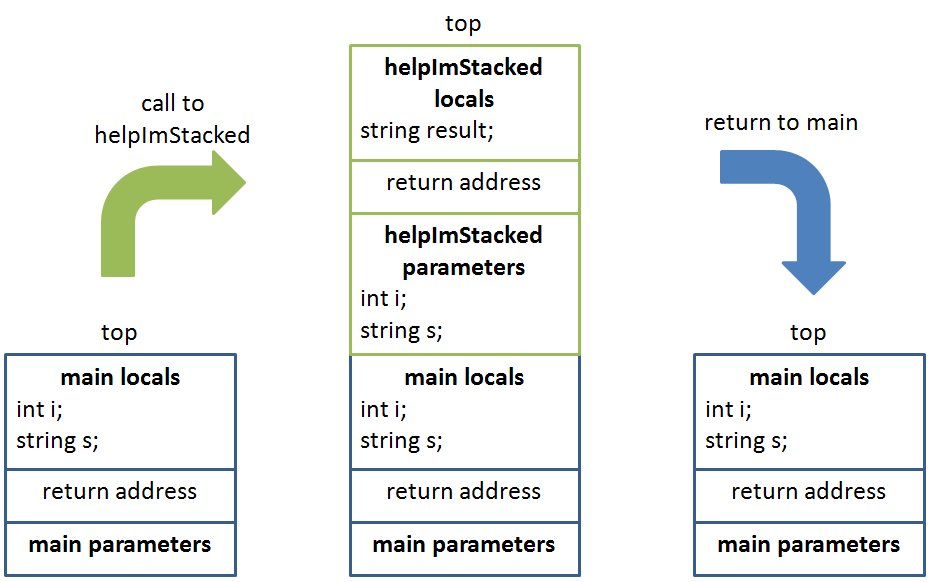
So, we see that we push the function's stack frame that we just called onto the top of the stack, and then pop it as soon as we need to return! Elegant...
Your GOSUB command coding will have to do something similar, but more basic; we don't require you to keep track of any variable states, but you DO have to keep track of the return addresses.
This is as simple as using your stack to keep track of the line number on which a GOSUB statement was called, and then returning to that line number after hitting a RETURN command.
Some final notes:
You will architecture your solution in terms of a base, abstract class Statement with concrete subclasses representing the individual statement types (where statements are different types of commands like ADD, LET, and PRINT)
You must implement a templated Stack class that is formatted as a linked list to use for your call stack; you may not use the STL implementation.